最近在和业务一起做压测,中间陆陆续续还是发现了一些问题,这里也一起汇总一下,看看压测中需要关注什么,也看看业务中常见的一些性能问题。
业务
日志行号
很多时候使用日志框架,都习惯性从网上复制一份日志配置,保证能正常输出就行。
举个栗子:
1 | |
其中,%L就是行号输出,这个配置项在日常定位问题时开启还是比较方便的,但是实际的计算成本很高的。

从结果上看,相同的压测并发量及数据集,在关闭行号后,CPU占用减少了9%左右。
无效日志
关闭行号后,发现日志的打印仍会占用5%左右的CPU,看了一下日志和火焰图,发现两个问题:
- 核心高流量接口,过多无效日志输出
- 预期内的业务异常,大量打印调用堆栈
其中对于堆栈的输出,如果在日志Pattern Format中没有指定的话,log4j2会默认在尾部追加%xEx来进行异常堆栈的格式化转换。Log4j – Log4j 2 Layouts

%xEx最终通过ExtendedThrowablePatternConverter进行堆栈打印,过程中涉及类加载、依赖JAR读取等操作,也会占用一部分CPU资源(火焰图中看到大约4%)。
如果要关闭所有的异常堆栈打印的话,可以在尾部追加%ex{0},但是并不建议这样做,在真正出现异常需要定位问题的时候,堆栈还是很有帮助的。所以这里还是建议,对业务异常,日志输出时不打印堆栈;对非预期异常,必须打印堆栈。
出于稳定性的考虑,我们决定在旺季来临时彻底关闭了INFO日志。
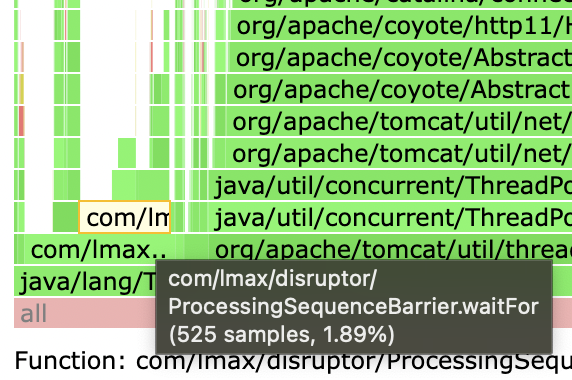
在压测中,我们也实际验证关闭后,已经几乎没有这部分的资源占用了。
(图中原log4j的cpu占用已经没有了)
循环调用
最常见的就是循环调用,调用如果涉及HTTP、RPC等,就会导致整体耗时较长。
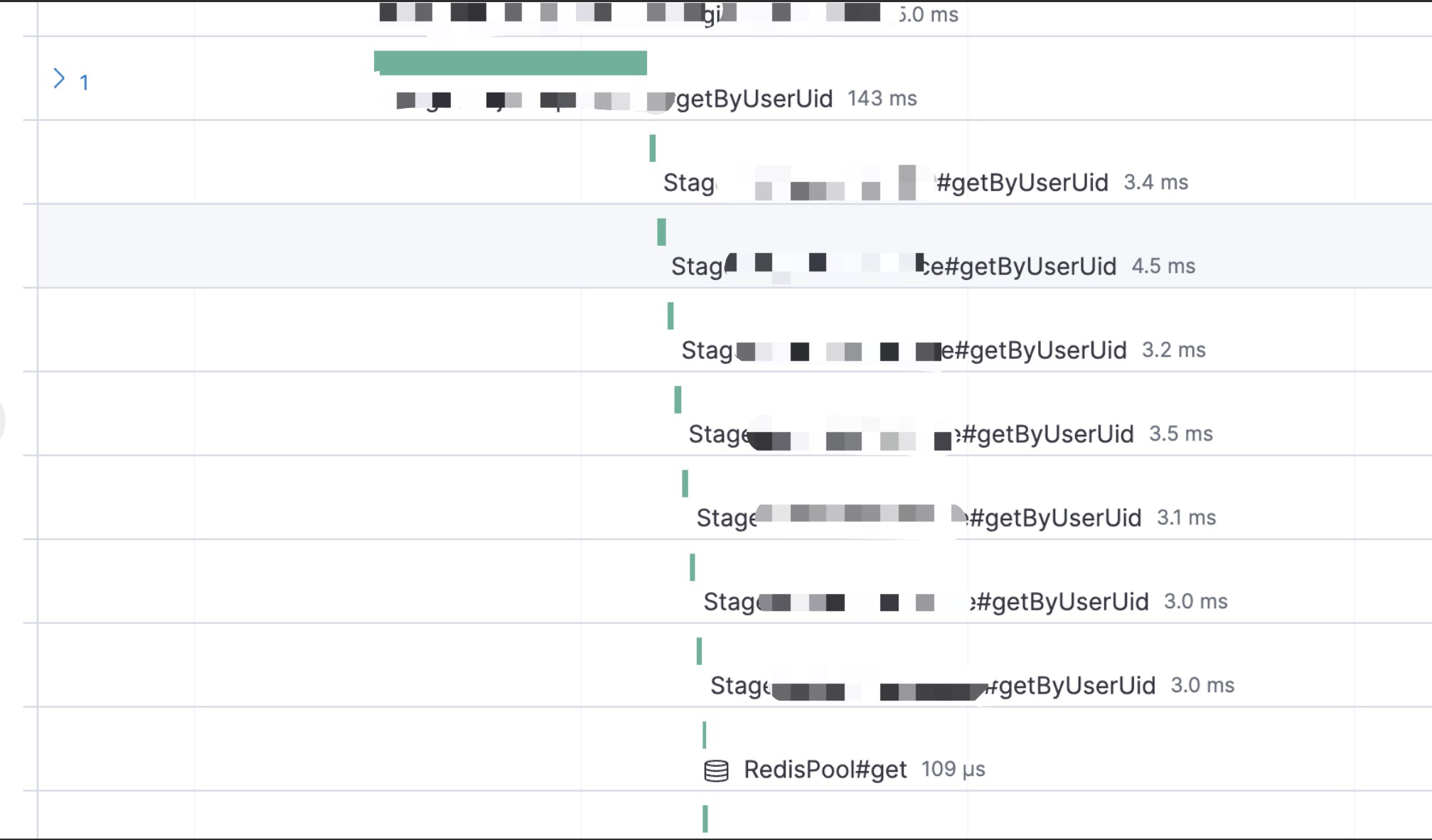
图中就是一个循环RPC调用的例子,解决方法也比较简单,循环改批量即可。
自建轮子填坑
压测中发现老项目用了一个公司内部的MySQL连接池,发现在获取连接时存在性能瓶颈,在连接数充足的情况下,getConnection耗时较高。
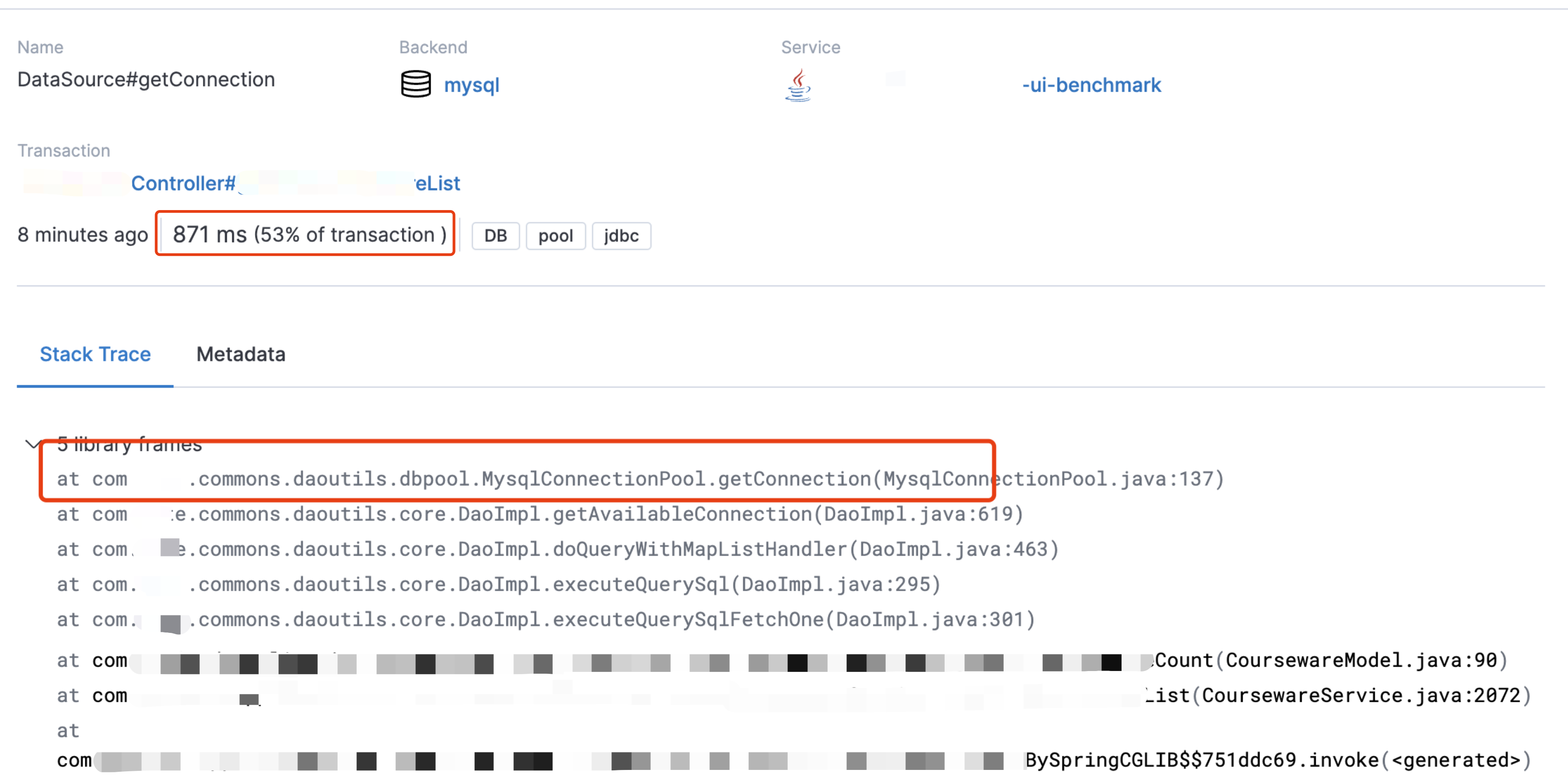
替换连接池后恢复正常。
资源ID设计优化
这次压测中,一个基础服务表的数据量较大,从MySQL迁到了TiDB。
而在TiDB的查询过程中,涉及多个资源ID的IN查询,查找资源ID的供应商及分区信息。由于在TiDB写入时,使用的是默认的自增ID进行Hash,因此数据在TiKV上的分布很随机,IN查询可能涉及多个节点查询,导致性能表现并不好。
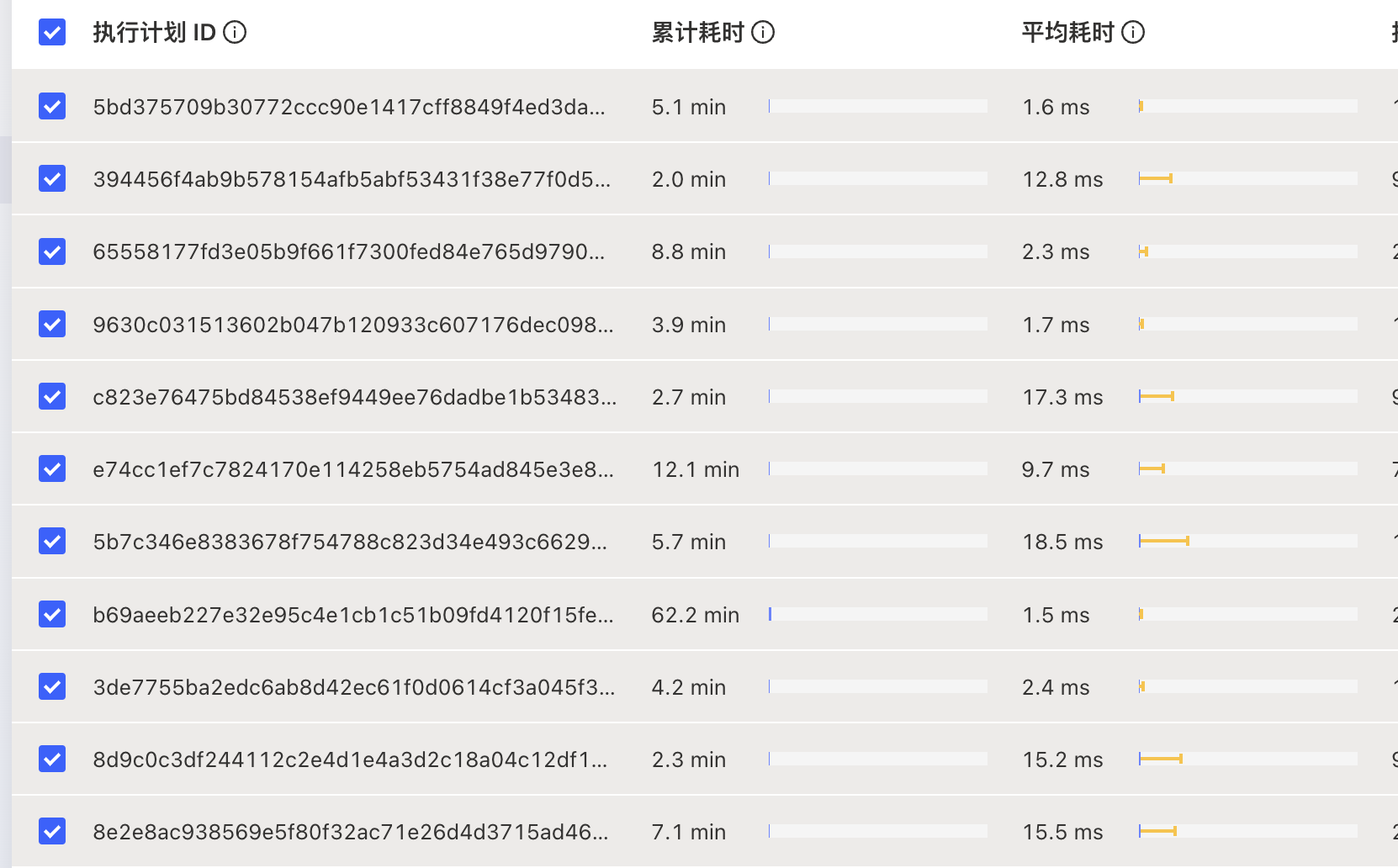
其中,SQL平均响应时间最高已经到了17ms,99线也达到40ms以上,涉及多节点的查询也找不到更好的优化方法。
在考虑了缓存、上层业务优化后,我们想到从ID设计下手,可以完全避免这个问题,即在资源ID前预留1个字节(实际4~6bit就可以),将供应商及分区信息写入这个字节,这样从ID上就能直接算出结果,完全避免了数据库查询。
(最终作为了一个长期优化方向,改造周期长,无法在旺季前完成)
第三方
阿里云OSS SDK高并发性能问题
在压测过程中,对慢接口的链路进行追踪,发现耗时都在oss sdk中有一个计算签名的方法里。
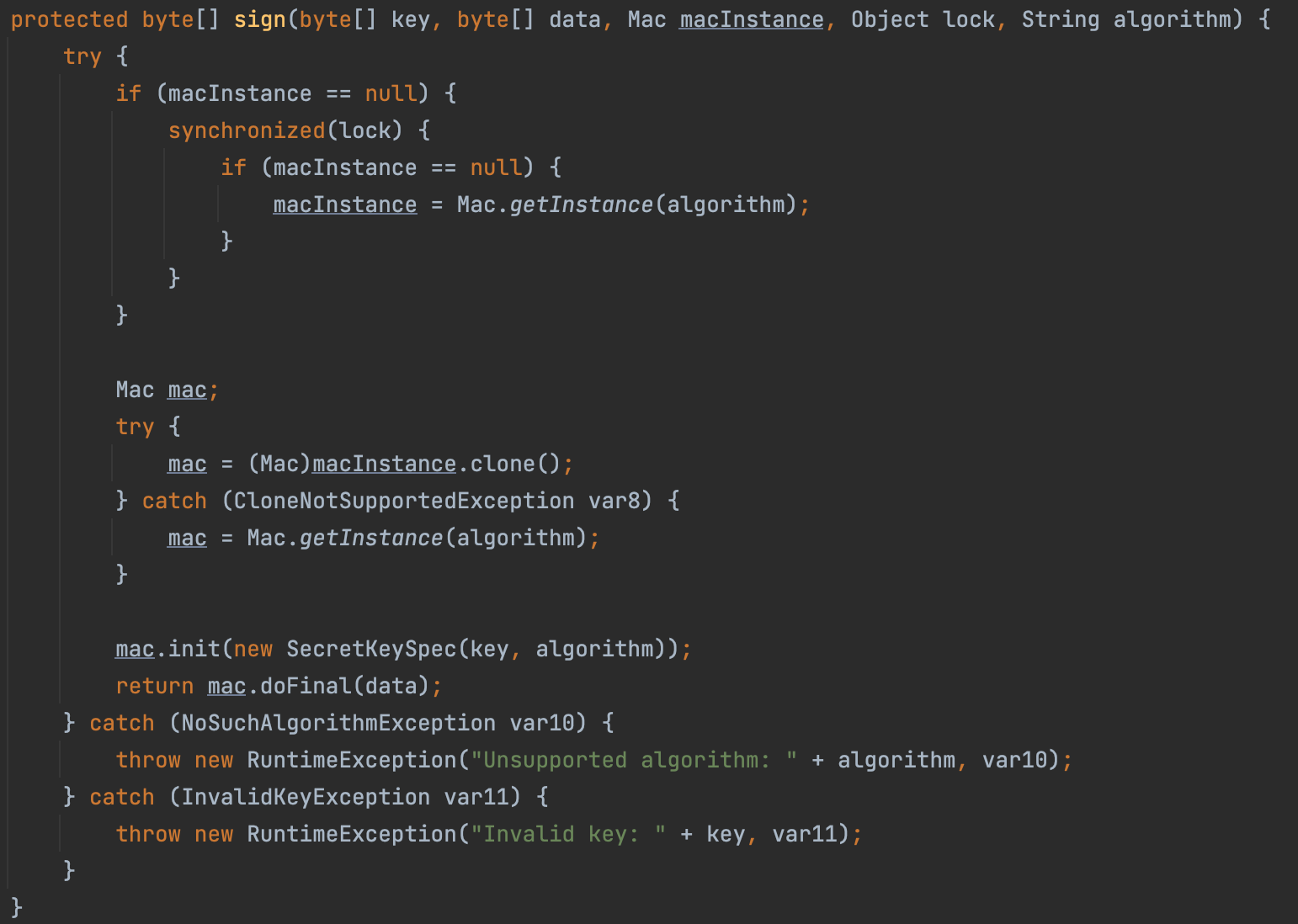
实际发现函数中的方法调用耗时都很短,但是整个函数执行时间比较长,所以怀疑是函数中的同步锁操作。
这里细看会发现是进行一个单例对象的的初始化,但是问题出在赋值的是一个函数入参,而Java中函数参数是值传递,所以这里的赋值并不会对调用上层的实际对象赋值,导致每一次进入函数时macInstance都是null。

正常情况下这里并不会有问题,但是在高并发场景下,多线程争夺lock锁就会有性能问题。
我使用的是3.15.0,对比了一下之前几个版本的SDK,发现旧版本2.8.x没有这个问题,应该也是官方的出发点也是想重构代码,把sign方法抽出到一个新的父类中,从而引发了这个问题,目前也已经提了Issue,等官方新版解决吧。(https://github.com/aliyun/aliyun-oss-java-sdk/issues/423)
压测环境
JMeter HTTP Client 配置
压测使用的JMeter,在压测过程中发现有很多CLOSE_WAIT连接。

进一步抓包,发现压测过程中大量肉鸡端发起的建连和断连。

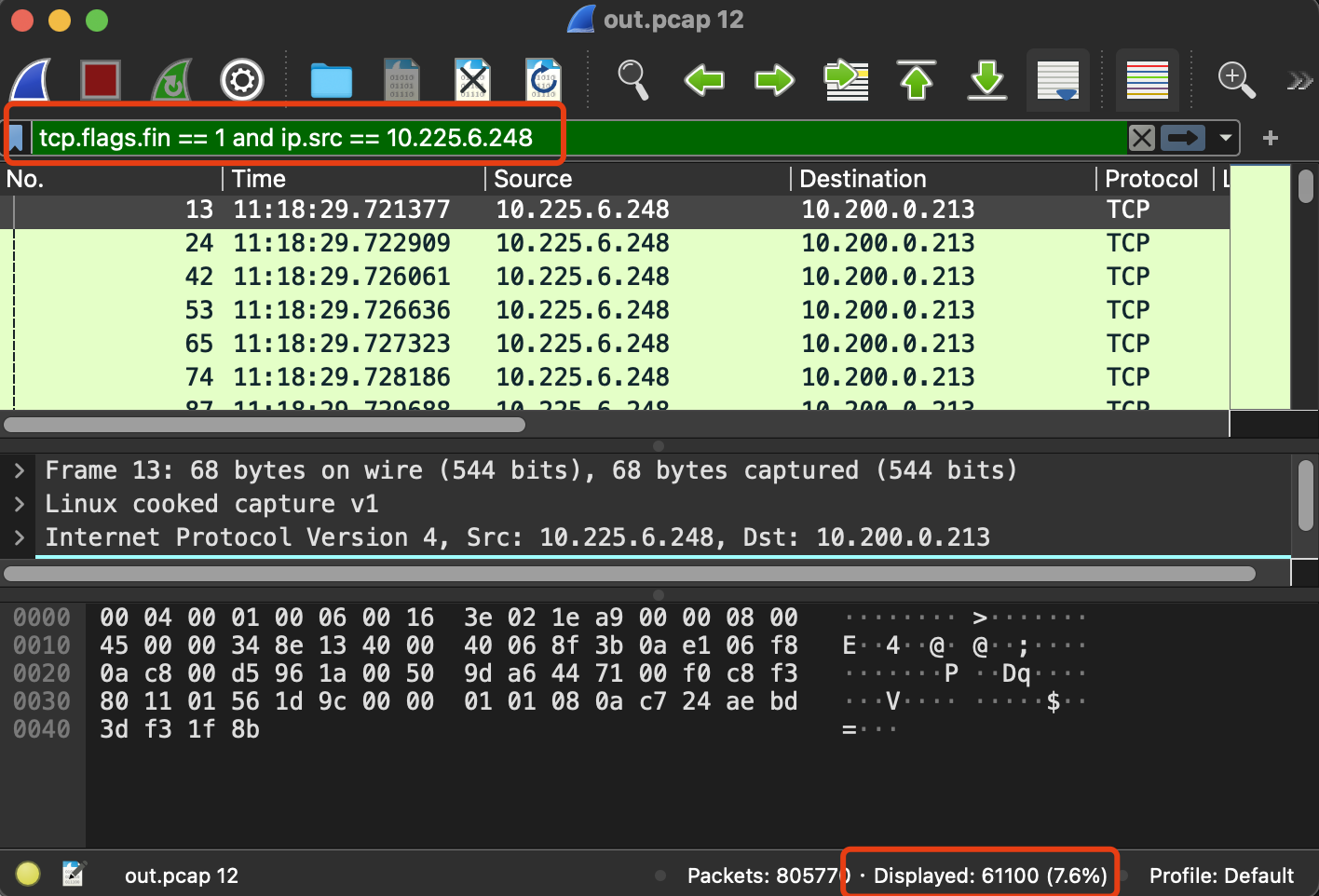
最终发现是JMeter脚本没有配置发起HTTP请求的Client类型。

这种情况下,默认使用httpclient,每一次HTTP请求都要重新建连,请求结束后断开连接,因此导致压测过程中大量建连断连。
这会带来额外开销,导致肉鸡能支持的并发数下降,同时也会带来另一个问题,tcp connect 端口大量消耗时带来的性能衰减。最终,我们将Client Implementation设置为Java,同时开启keep-alive,类似现象就不再出现。


tcp connect 端口大量消耗时带来的性能衰减
由大佬提供,在进行connect时,linux默认优先遍历选择偶数端口,耗尽后再遍历奇数端口。容易带来的一个问题时,在端口大量消耗时,偶数端口耗尽,每一次connect都将遍历所有的偶数端口,再在奇数端口中遍历找到可用端口,带来性能的衰减。
业务实例压力评估
在最开始做单场景/接口压测时,WEB服务属于是IO密集型,一个请求的大部分时间在等待DB、第三方调用等行为上,因此实际单实例能支撑的并发数应该是远大于核数的。
最初在评估业务实例的压力时,更多尝试观察CPU使用率是否到达瓶颈。但是,随着压测压力的提升,部分实例出现CPU使用率未满,但是吞吐量始终无法增加的情况,并且随着并发数的增加,CPU仍然未满,且吞吐量反而下降。
这里陷入的错误是,不能以只以CPU使用率来评估,还需要观察Load Average。
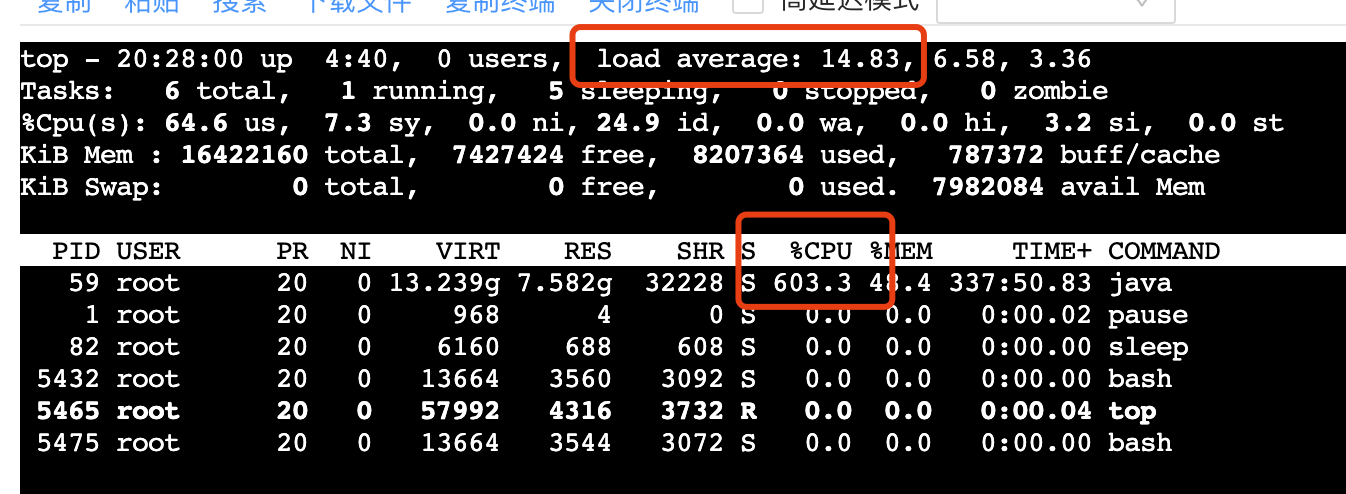
在容器配置8核的情况下,CPU只跑在600%左右,而最近1分钟的Load已经到了14+,说明有6+线程处于RUNNABLE状态且等待被CPU执行,当前负载超过可承载量。

同时也可以发现cs已经达到5w+,上下文切换频繁也导致CPU空闲时间上升,最终无法跑满CPU。
关于cs有一个数据可以参考,压测了一台8核的
apisix,upstream为空的情况下,qps max到5w左右,此时cpu基本跑满,load在10左右(多出来的2为一些监控指标收集线程),cpu基本都在跑work process,cs只有8000左右。
容器内Load不准确
top命令看到的数据,是通过读取/prof/stat获得的,而容器中的该目录实际是挂在的宿主机目录,所以top看到的Load Average实际是宿主机负载。
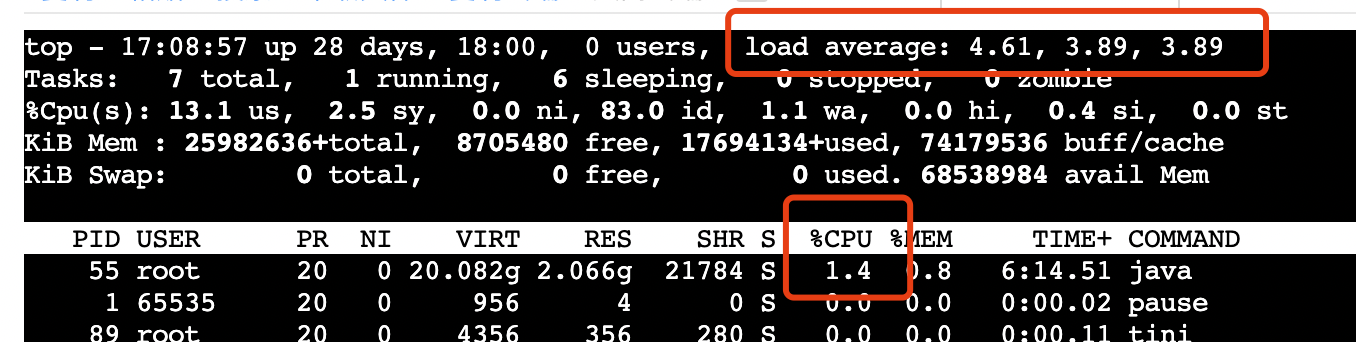
可以看到容器内我们的进程并没有在使用CPU,但是看到的Load Average确比较高。
如果想要看到相对准确的负载信息,可以通过cAdvisor中采集的Load,或者通过大佬修改的ctop来查看。
ctop - GitHub
https://github.com/arthur-zhang/ctop关于Load的计算逻辑可以参考这里
Linux Load Averages: Solving the Mystery
总结
这次压测的几个服务都是比较老的基础服务,之前经历过多次压测,优化也做的比较好,所以发现的业务问题并不多。
同时,这个过程也让我们发现在压测过程中,在基础压测环境及实例压力的评估、压测流程的规范上还有待提升。
(后面再整理一次自己对于压测流程的整理)