对,没错,又是我。
对,没错,又是压测。
对,这次又发现了新的问题。

最近从11月下旬开始,就对一些业务服务做了压测,包含HTTP及Dubbo的服务。这次发现的问题更多不在业务服务上,而是在压测的基础环境及工具上,这些问题也直接导致了压测数据不准、压测资源利用不足等问题。
先概览性的看看这些问题:
- JMeter Dubbo插件
jmeter-plugins-for-apache-dubbo在2.7.4版本下性能问题,导致单台肉鸡实际在执行的并发线程数较少 - 服务实例、中间件及存储不在同一个服务器区,导致网络延迟较大,压测结果和实际存在偏差
- JMeter InfluxDB插件在并发场景下,会导致统计的吞吐量及线程数错误
有兴趣的同学可以看看顺着往下,一起讨论细节和解决方案~
JMeter Dubbo插件性能问题
jmeter-plugins-for-apache-dubbo是为JMeter下的Dubbo插件,可以直接对Dubbo接口进行压测,并提供部分可视化操作界面,操作十分简便。
目前在Github上搜索Jmeter和Dubbo时,排在最前面的就是这个插件了,同时项目也获得了540 Star。
由于我们的很多基础服务都是对内提供的Dubbo接口进行调用,因此针对这部分服务的压测也自然使用到了该插件进行压测。
同时,由于我们服务的Dubbo版本比较低,还是2.6.x ~ 2.7.x,所以只能使用该插件的2.7.4版本,以此来支持旧版本Dubbo。
但是在压测过程中,发现肉鸡CPU使用率始终很低,使用的核心数不超过3个。

这就让我比较困惑了,肉鸡容器是8C6GB的配置,在并发数配置足够的情况下,应该不会这么低才对。
抱着好奇的心我Dump了一下线程堆栈,看看到底这些线程到底在干什么。
线程堆栈分析
Dump出来的线程堆栈比较多,除了Netty的Work线程池外,还有DubboServerHandler、GC Thread Pool及APM等。
这一下直接看的头大,还是先把RUNNABLE线程捞出来看看,看看哪些线程是勤劳的在工作的。
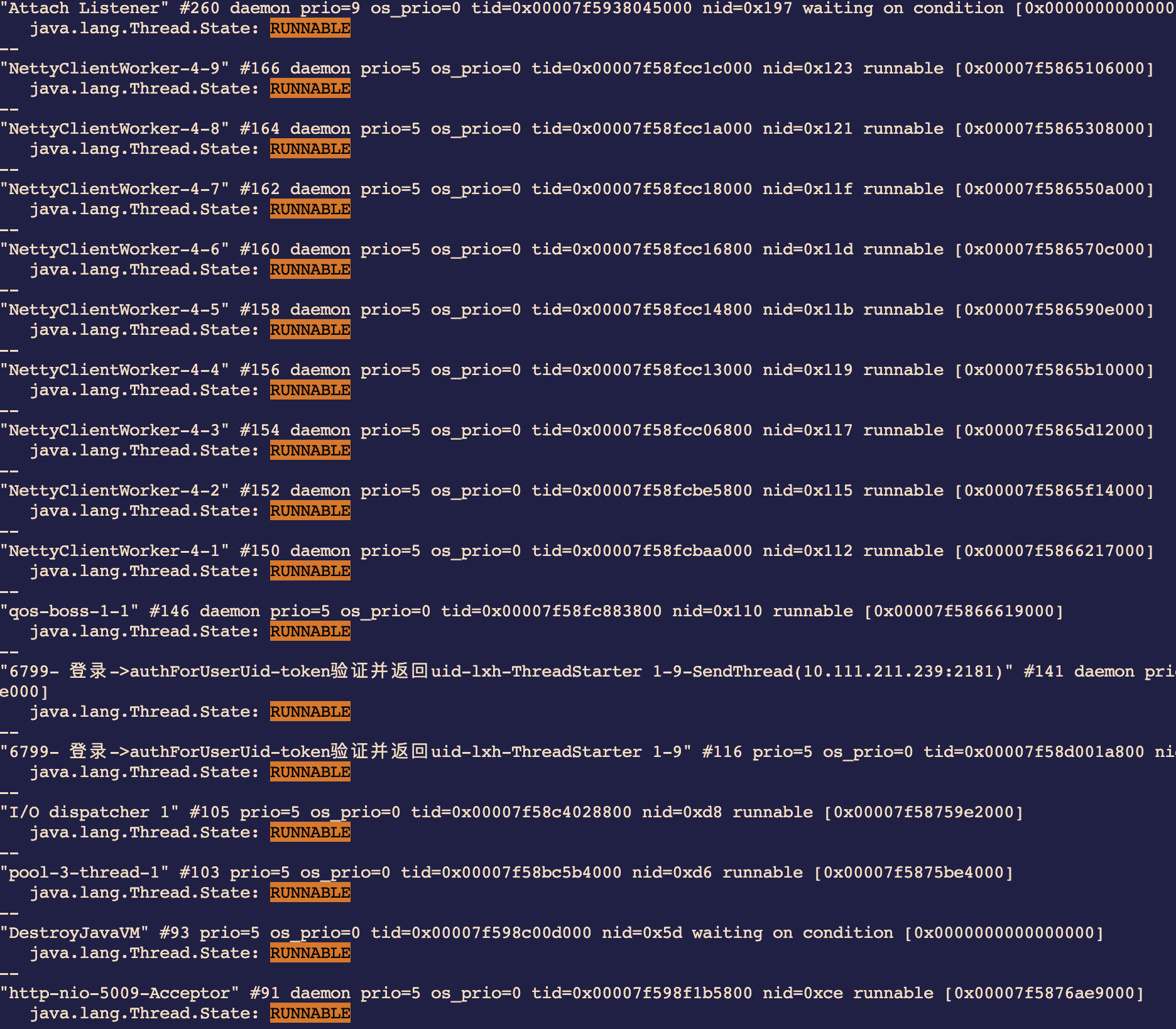
可以看到,大部分处于RUNNABLE的线程都是Netty的线程池,而压测线程只有两个处于RUNNABLE。这就和配置对不上了,实际压测线程配置了30,那么其他的线程在干什么呢?
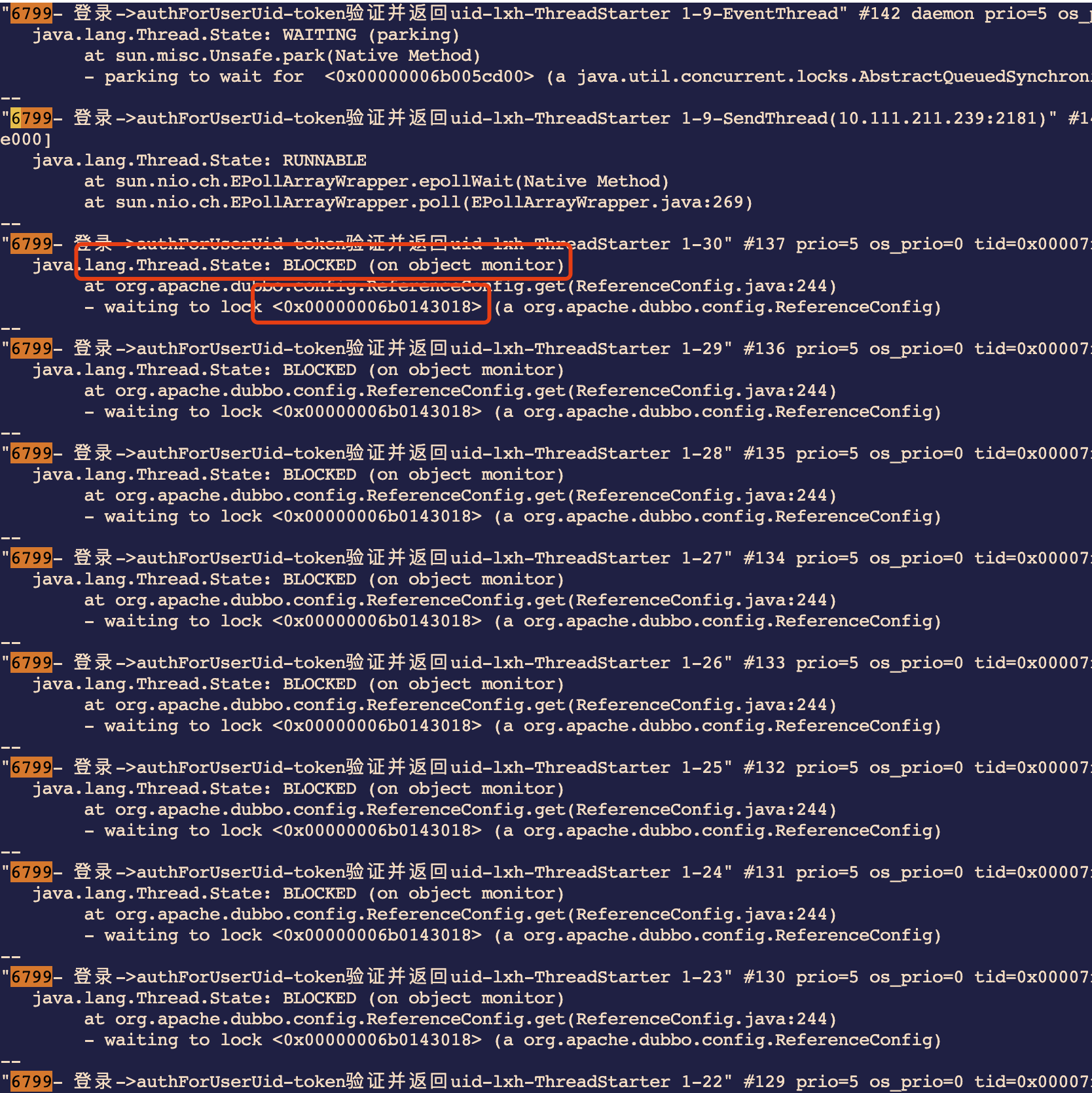
剩下的线程基本都处于BLOCKED状态,并且都在等待同一个ReferenceConfig对象0x00000006b0143018。
这下就清楚了,并发场景下出现了资源争夺的情况。
资源争夺
既然知道是争夺某个资源,那么看看这个资源到底是什么。
在jmeter-plugins-for-apache-dubbo中,每次压测请求实际就是一次sample。在每次DubboSampler进行sample发起请求时,都会重新创建ReferenceConfig并进行初始化。
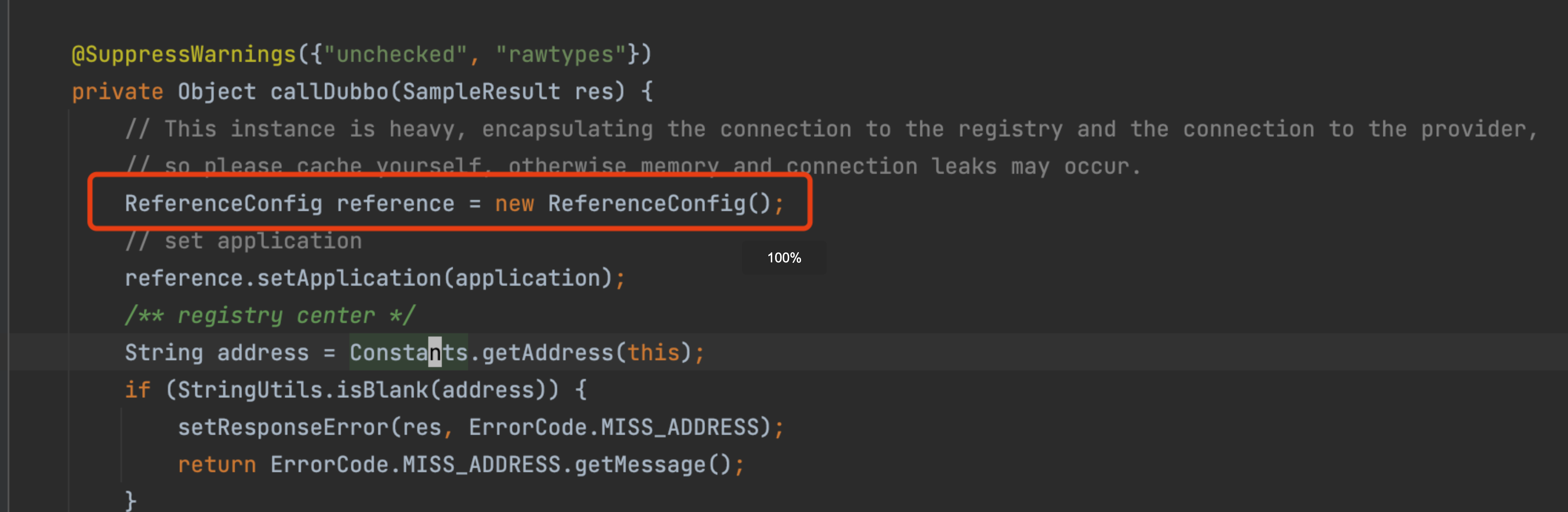
同时,会通过该Config对象重新从ReferenceConfigCache中重新获取服务对象。
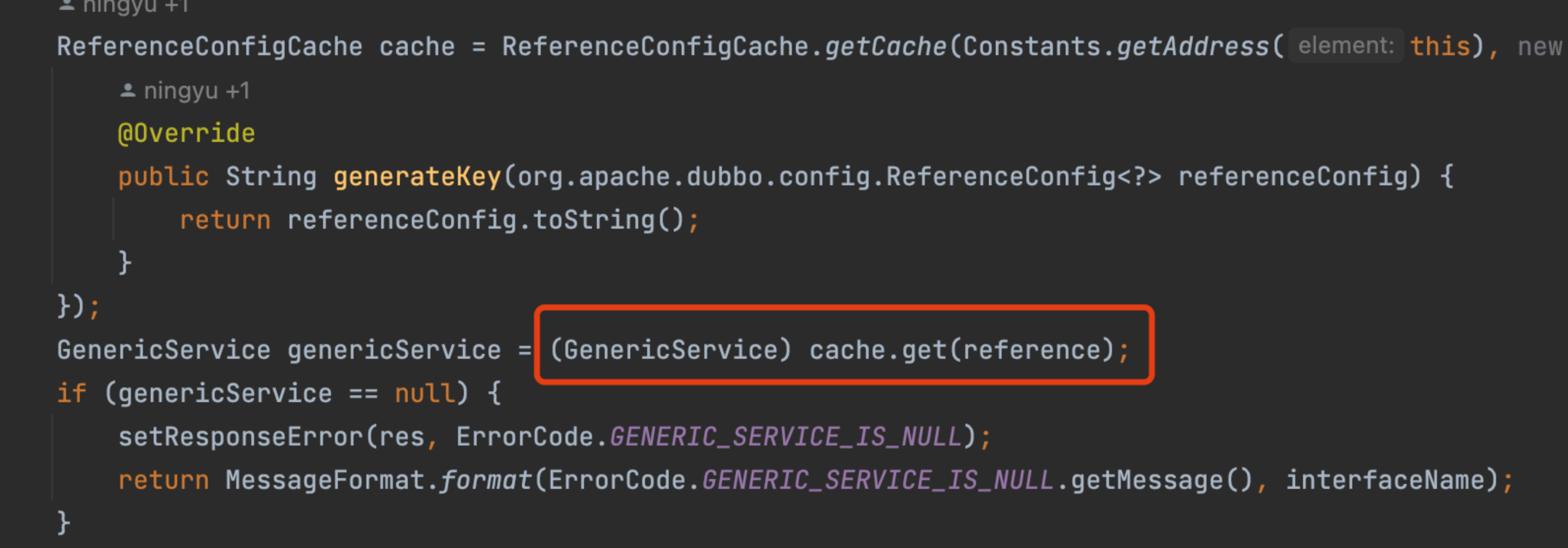
在ReferenceConfigCache.get()过程中,如果referenceConfig已经生成过(会生成一个唯一key作为主键进行判断),就不会重新创建。同时,取出后会调用ReferenceConfig的get()获取service实例,而该get方法为synchronize方法。
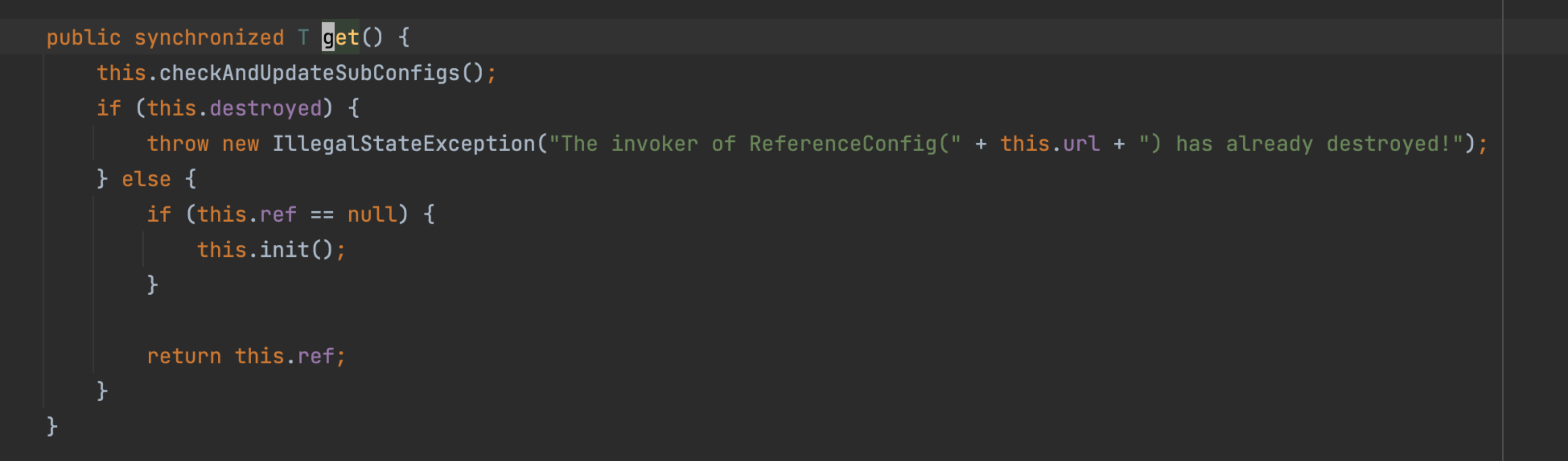
由于不同的线程都会从Cache中获取到同一个ReferenceConfig,并调用get()方法获取service实例,此时当该方法执行时间较长时,就会出现大量线程阻塞的情况。
取缓存也会慢?
争夺的资源找到了,但是也让人困惑。
从内存缓存中获取一个对象,正常说速度应该很快,为什么会有这么多线程依然处于BLOCKED状态呢?
关键就在其中的一个方法,checkAndUpdateSubConfigs()。

该方法在Dubbo-2.7加入,主要在service对象创建后调用,检查各个配置模块是否创建,并在必要的情况下覆盖一些配置。而在该方法中,除了基础的配置检查外,还有很多状态的更新,包括provider、consumer、registry及接口方法等,是一个相对较重的操作,因此导致该方法执行时间较长。
而从实际该方法的职责来看,也只应该在service对象首次创建的时候调用,而不是每次获取service对象缓存时都去检查,在最新的Dubbo版本中,也从该方法里移除了checkAndUpdateSubConfigs()的调用。
问题小结
综上所述,在多线程并发发压的场景下(jmeter-plugins-for-apache-dubbod的2.7.4版本中),由于Dubbo中ReferenceConfig中的service对象被多线程共用,而获取该对象的ReferenceConfig.get()为synchronize方法,因此产生了资源争夺。
解决方案
其实最简单的解决方案是升级jmeter-plugins-for-apache-dubbo到最新版本,该插件最新版本引入的Dubbo版本也较新,已经解决了该问题。
但是,对于来说比较尴尬,Dubbo版本比较旧,无法直接通过升级插件的方式解决。
于是小小的改了一把插件源码,就是将获取的service对象进行缓存,不用每次都新建ReferenceConfig来从cache中获取。
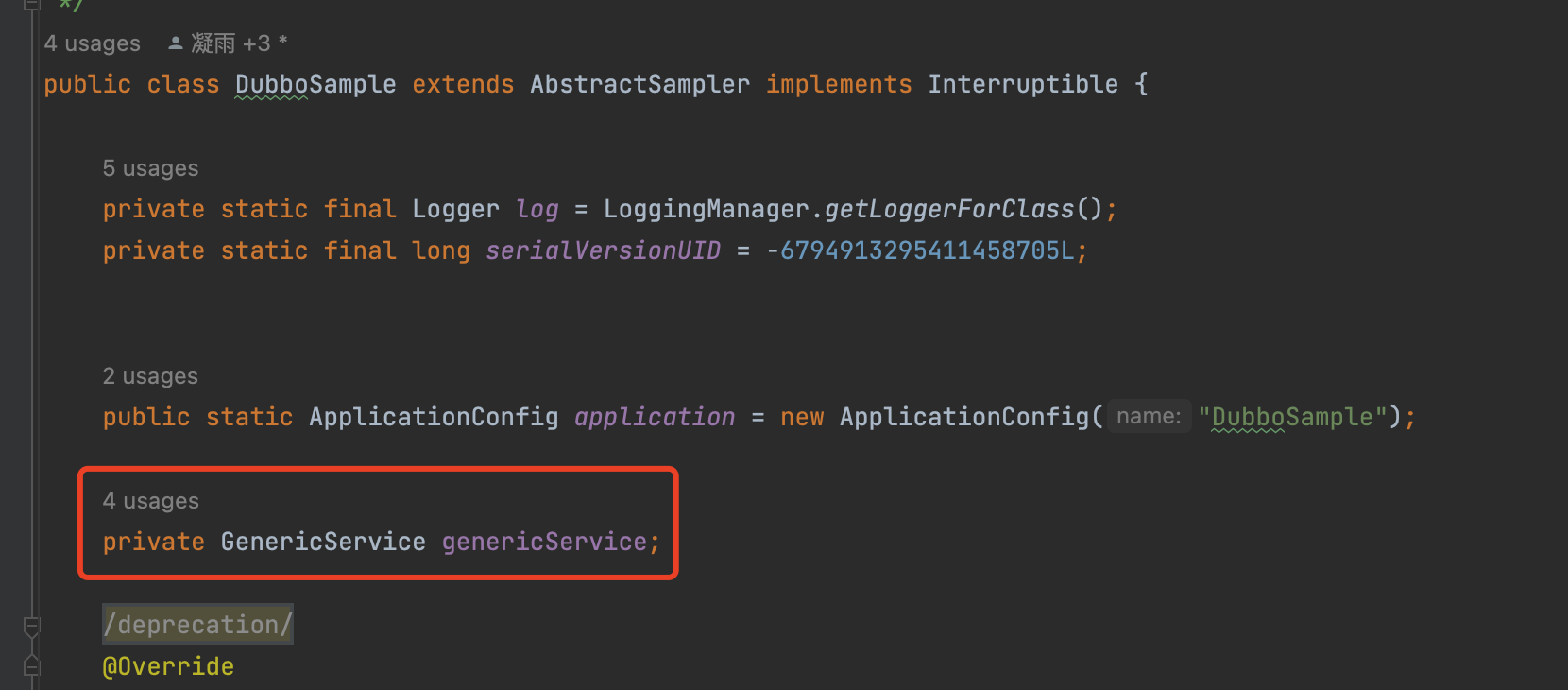
改动后的效果也很明显。

相同配置的肉鸡和并发数,抛出来的吞吐量相差至少8倍。
JMeter InfluxDB插件并发统计错误
我们的肉鸡发压端是通过JMeter实现的,同时使用了InfluxDB插件进行压测数据的记录。
但是在实际压测过程中,启动多台肉鸡的情况下,经常出现相同肉鸡及并发的场景下,吞吐量及活跃线程数不稳定的情况。

从图中可以看出,在相同发压配置的情况下,吞吐量和活跃线程数浮动较大。
在平均响应时间为6ms的情况下,单线程QPS应该在166左右,总计240并发应该可以跑到4W QPS左右。而实际上结果却在3~4W之间波动。
这就很困惑了,难道JMeter有bug,会导致发压不稳定?
线程分析
既然活跃线程数有波动,那么同样看一把线程dump。

其中肉鸡JVM中启动压测相关的线程共计43个,其中2个ZK线程、1个Netty线程,剩下40个均为压测发压线程,实际线程数与配置相同。
这就让人更困惑了,明明线程数是对的,为什么统计数据就有波动呢?

数据校验
如果配置和实际现场都没有问题,那么有没有可能是统计的数据不准呢?
为了验证这个想法,我通过APM的统计数据进行的验证。
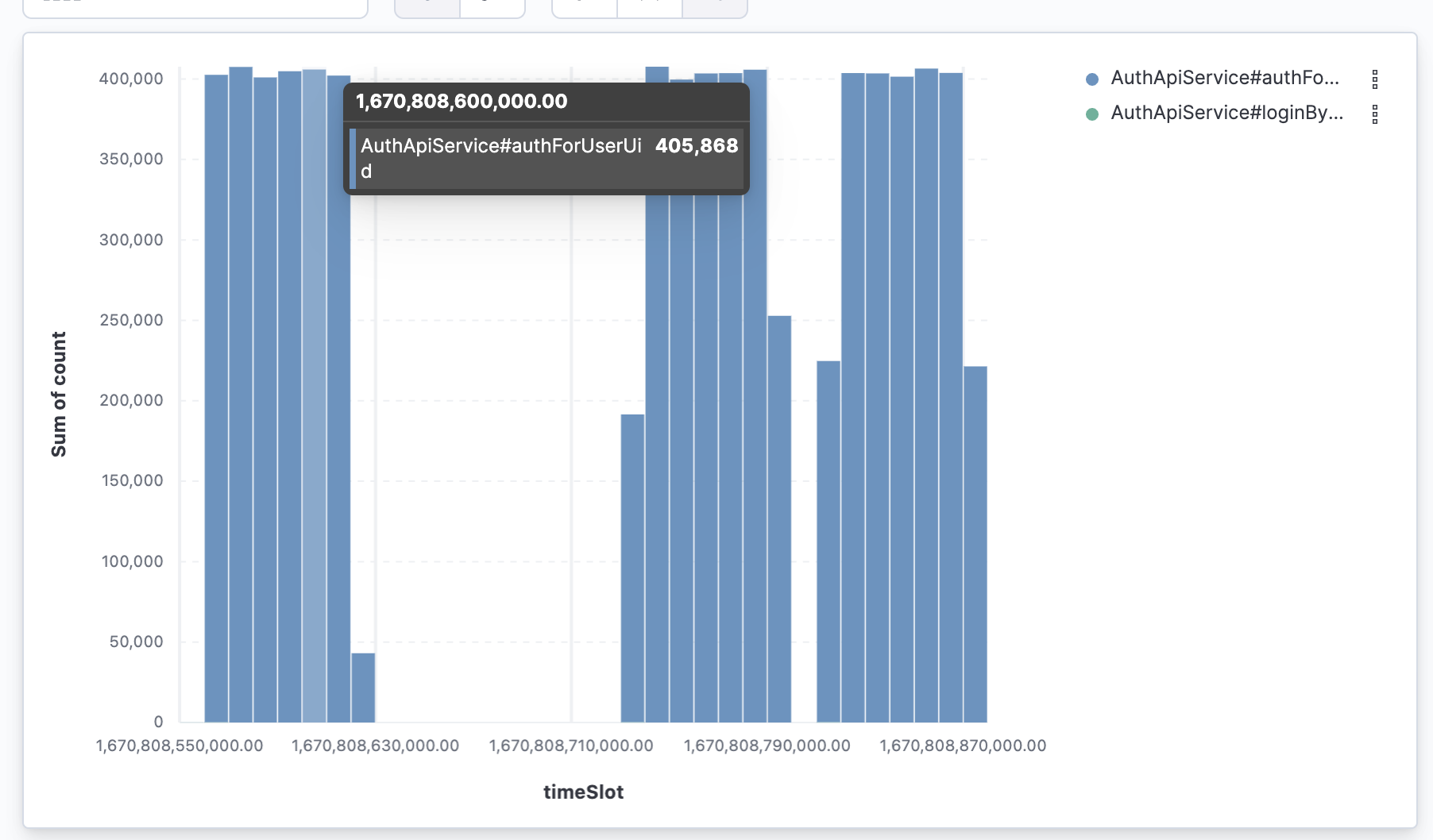
基于APM的拓扑统计数据,10s一次聚合,判断APM记录的QPS在4W左右,和我们推测的预期QPS一直,说明实际上的发压流量和预期相符合。
而实际上压测监控看板中的吞吐量只有3.5W左右,且浮动较大,说明是JMeter统计数据可能存在问题。
根因分析
既然是通过InfluxDB记录的数据,那么先看看库中的数据是怎样的。

InfluxDB中的数据以纳秒为单位,每5s记录一次。
但是从库中数据来看,抽取某次统计时间的数据中,只有3条数据,实际应该是和肉鸡数相同的4条,说明数据写入存在问题导致数据不准确。
那么为什么4台肉鸡,在相同的时间只写入了3条呢?
首先想到的就是数据重复被覆盖,这就涉及到InfluxDB的数据存储逻辑。
在InfluxDB中,单条数据通过timestamp + tag进行判重,如果重复将对value进行覆盖。
而JMeter写入InfluxDB中的数据里,以application + transaction + staut + userTag作为 tag 进行写入。
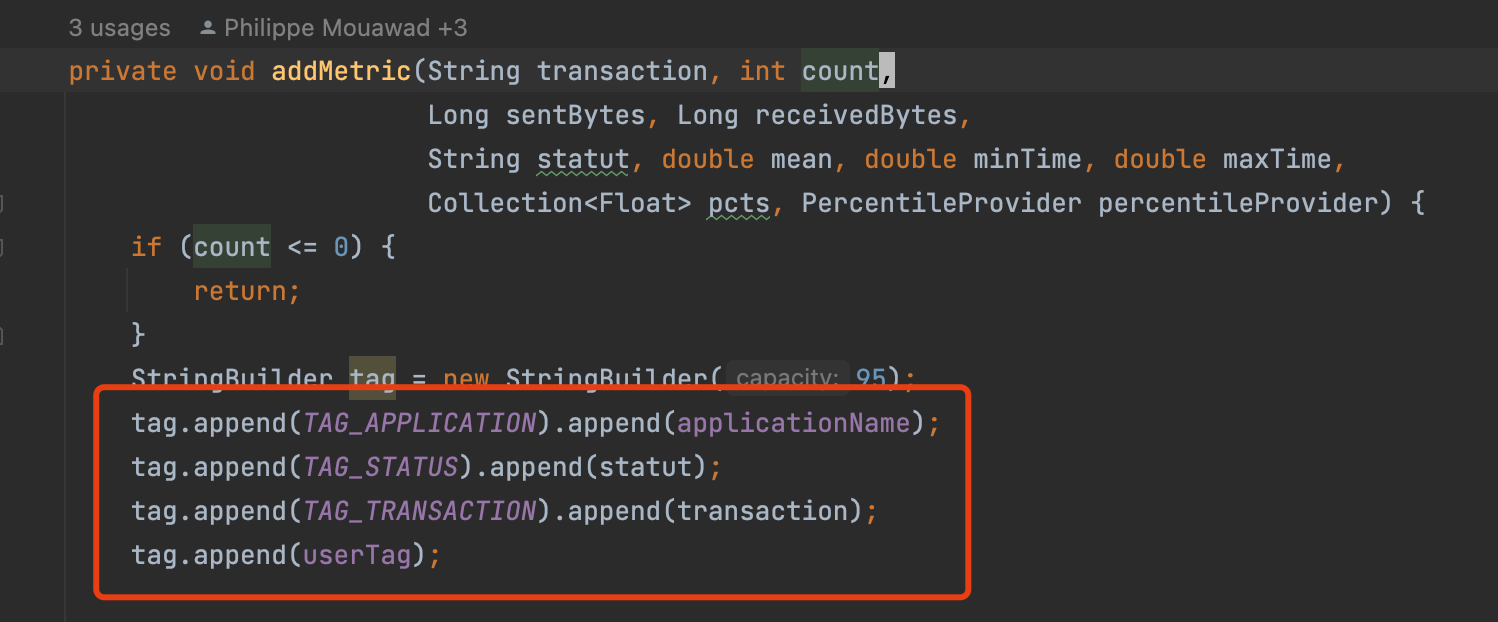
其中,application为固定值“ALL_VER”,transaction为固定值”6799-xxxx”,statut为固定值””(空字符串),userTag为固定的空集合。
因此,可以理解为每条数据的tag均相同,若timestamp出现重复,则数据一定会被覆盖。而在多台肉鸡的情况下,在ms级别出现相同时间戳写入的概率极高(都是5s为周期进行写入,服务器间时间同步)。
想法验证
既然可能是tag重复导致,那么最直接的方法就是让不同肉鸡的tag不重复即可。
刚才我们有提到,InfluxDB中的数据里,以application + transaction + staut + userTag作为 tag 进行写入,而其中的userTag就是用户自定义的Tag,只要保证每台肉鸡的自定义Tag不同就可以实现。
- 那么怎么设置userTag呢?
在InfluxDB插件中,在传入的参数中,只要以TAG_开头就会被识别为userTag。

- 那么不同肉鸡如何区分tag呢?
最简单的方法,加入IP + Port。
不同的肉鸡,其IP + Port肯定不同,只要将其设置为自定义的userTag即可。

改动很简单,修改完成后,写入的数据增加了一列instance描述肉鸡信息。
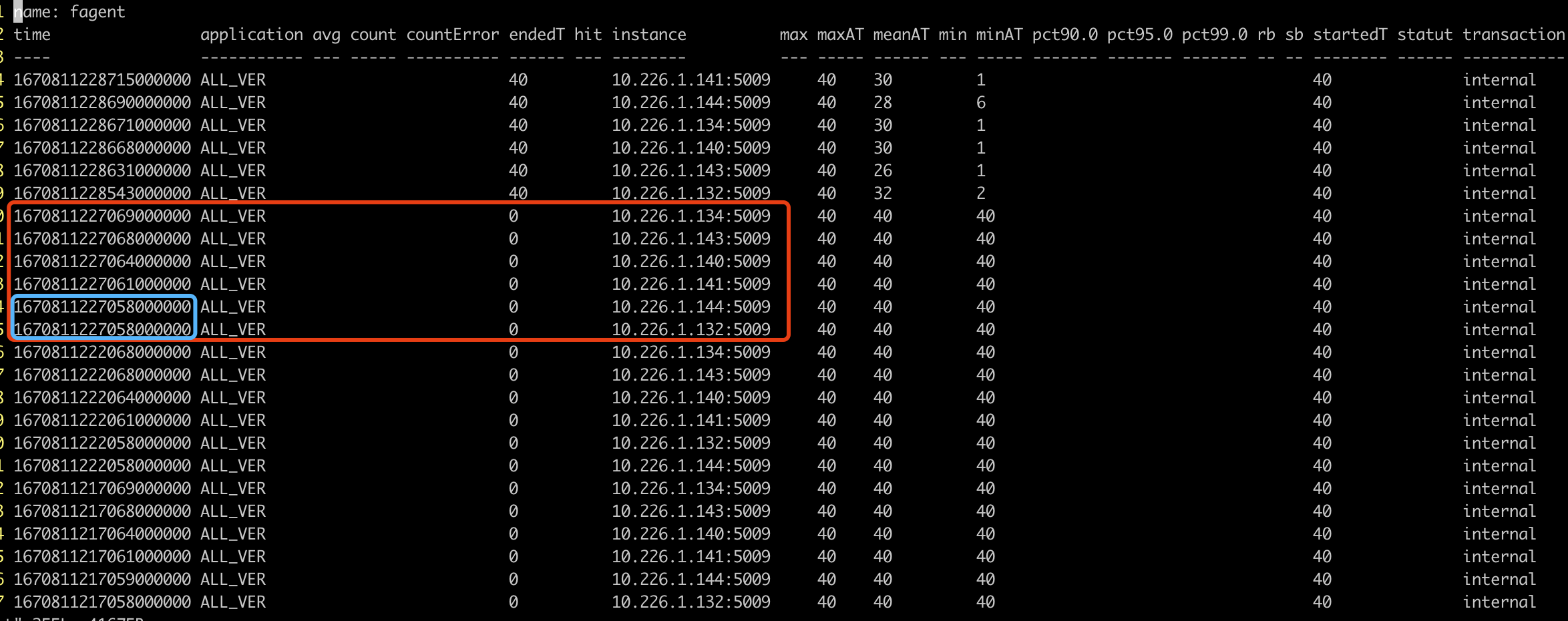
从图中的蓝框也可以看到,实际确实存在相同ms级时间戳的出现,而在加入了IP + Port后,将这两条数据区分开了。
再进行实际压测验证,流量和活跃线程数已经非常平稳了,且数据统计结果与APM一致。
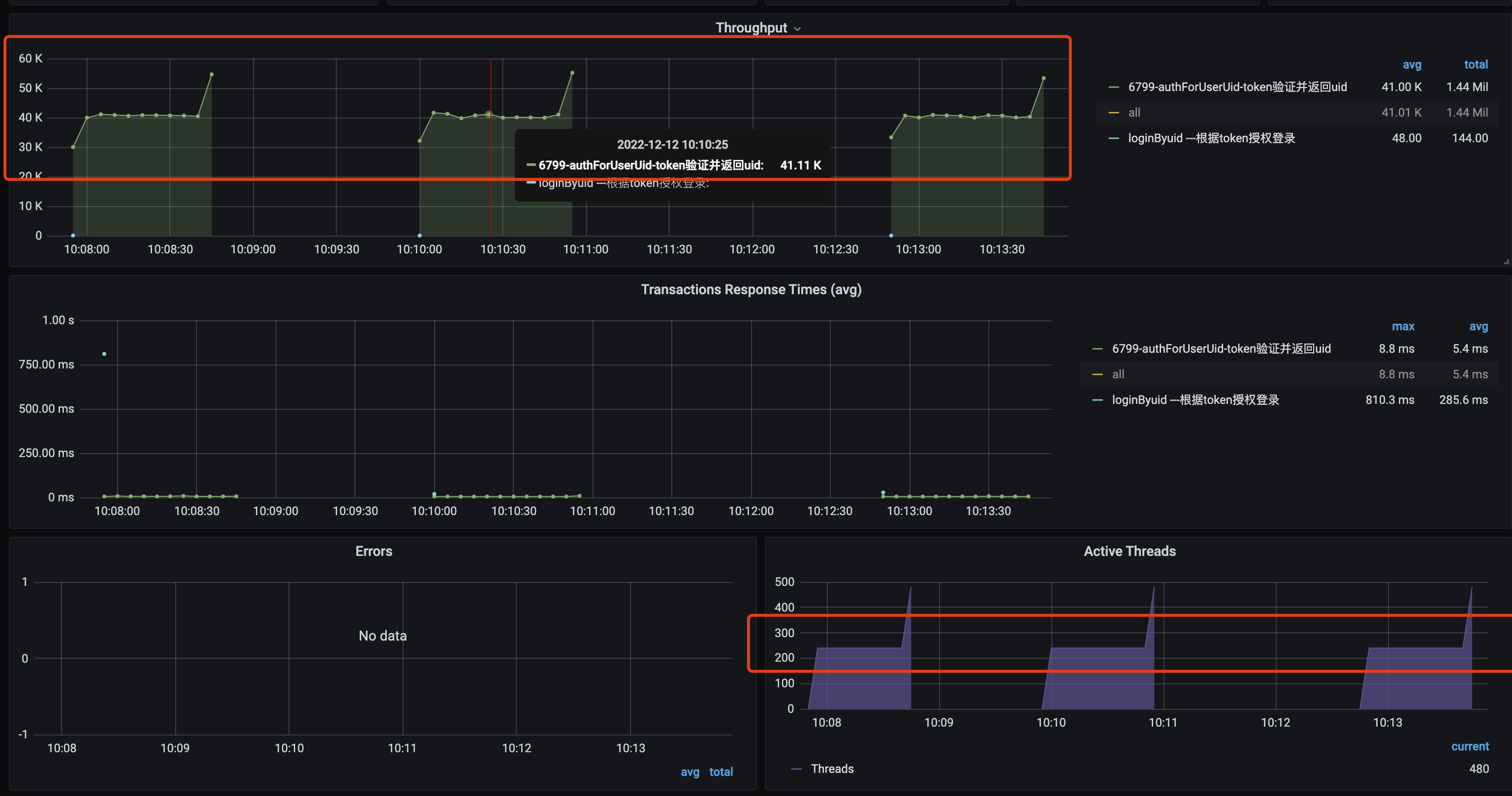

开头和结尾会不平稳,主要是因为5s周期统计的问题,压测开始和结束的时间可能在5s周期的中间开启。例如,19:00:03开始,而实际统计周期是19:00:00~19:00:05。
问题小结
JMeter InfluxDB插件并发统计错误,主要是由于多台肉鸡同时发压时,存在timestamp + tag相同的统计数据,结果导致先写入的数据因主键相同被覆盖写入,导致统计数据不准。
服务及各组件不在同一个服务器区
这个问题是偶然运维的同学发现的,我们压测的容器是使用的阿里云ECI,正常来说都是会调度到同一个服务器区,我们服务的请求链路也比较简单。
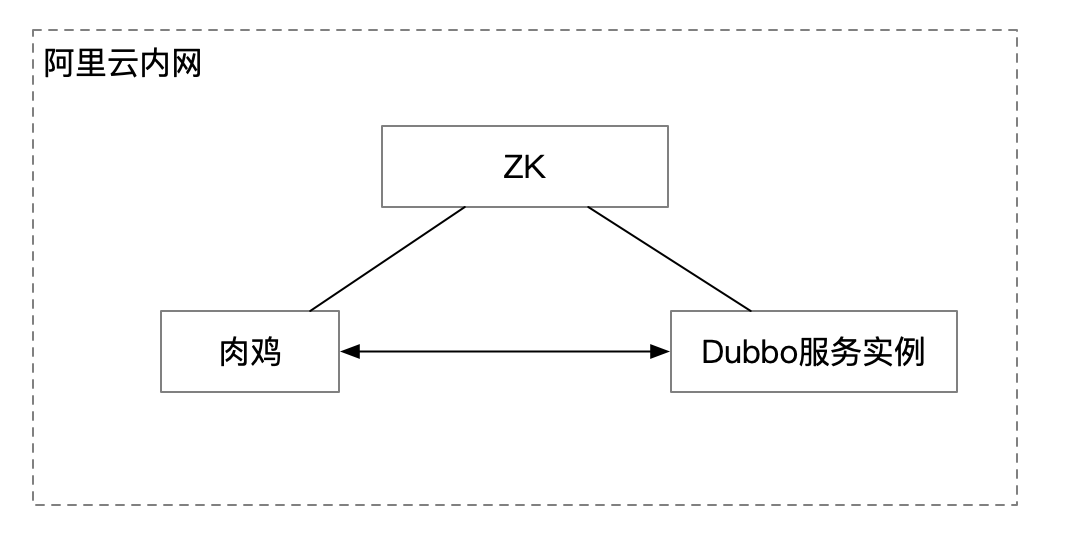
正常情况下,如果在同一个局域网内,主机之间的网络通信速度是很快的,一次请求的时间在0.1ms~0.2ms左右。
下图就是同一局域网内,两台主机之间的ping结果。
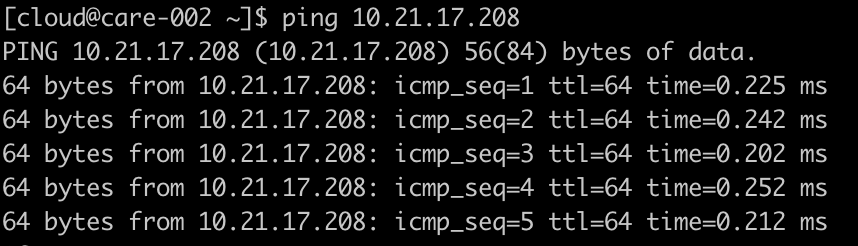
在实际的压测过程中,我们发现两台主机之间的网络耗时有时达到2ms以上。
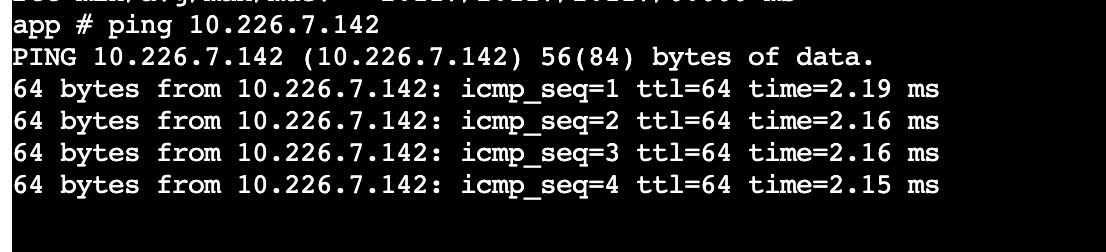
看上去好像耗时都不多,实际在高并发压测的场景下,对结果还是有影响的,相同肉鸡及并发数产生的压测QPS会偏差很大。
最终在联系了阿里云的同学排查后,确认ECI并不保证实际分配的容器实例与配置的服务器区是同一个,只会保证基础的网络互通。所以实际分配的容器实例可能在另一个服务器区,中间的网络耗时就升高了很多。