好不容易经过了旺季,陆陆续续也经历了Redis数据节点出口带宽、ES节点负载倾斜宕机等故障的发生,对于线上基础设施和组件的问题关注也越来越多。
这次发现的问题来自APM Agent,我们服务层级的监控是基于Elastic APM Java Agent实现的,在其基础之上做了一些扩展。Elastic APM从2018年开始release 1.0.0版本,至今也已经过去多年,原本以为已经相对稳定,但是还是翻车在SpanPool用到的MpscAtomicArrayQueue上。
问题现象
今年旺季后,用户量再次上涨,随即有业务反馈线上服务出现99线尖刺,甚至导致服务出现瞬间限流。

由于该服务为基础服务,被上层业务依赖,对上层的影响较大,直接导致上层业务降级。
问题分析
由于是概率性偶发问题,无法稳定复现并获取现场,所以只能先尝试猜测原因并验证。
猜测与验证
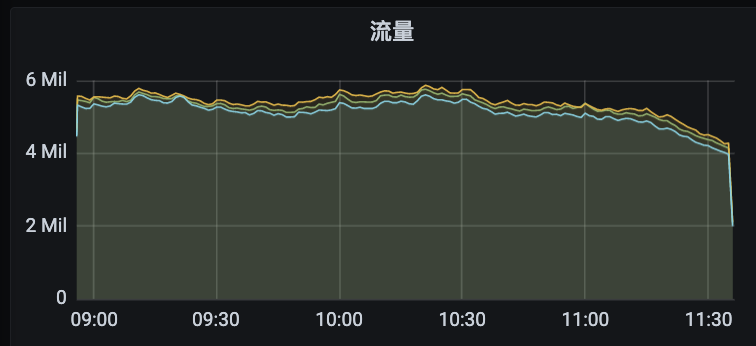
(一)是否存在瞬间流量导致负载短时升高?
不存在瞬时高流量,通过流量曲线图看到流量稳定。
(二)依赖中间件、存储是否存在慢查询/操作?
业务逻辑比较简单,依赖的组件只有Redis和MySQL,排查未发现慢命令/SQL。
(三)服务本身是否可能存在CPU密集型操作?
代码本身非常简单,只做数据写入读取,无计算逻辑。
(四)是否服务本身负载已到临界点?
查看服务集群负载,发现CPU使用率不超过35%,但是在服务出现限流的时间点,部分实例出现瞬间高负载的情况。

同时,进入实例查看发现在高负载时间点,DubboServerHandler线程池耗尽,触发线程池拒绝策略,自动dump了JVM中所有线程的堆栈。
拿到堆栈的我大腿一拍,以为真相就在眼前。
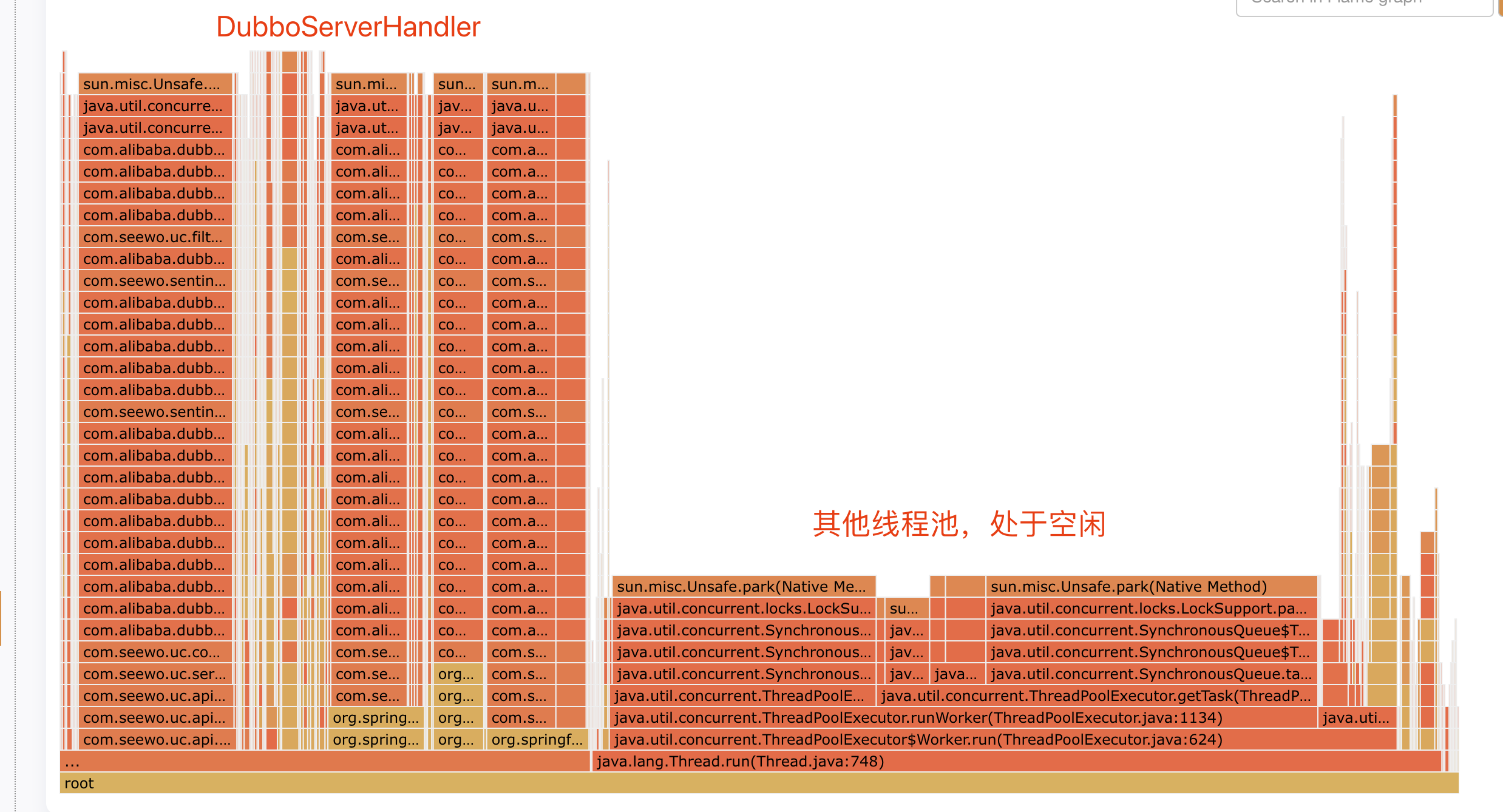
但实际上作用并不大,从堆栈上看分为两类,一类是DubboServerHandler,正在进行业务逻辑处理;另一类其他场景的线程池,基本空闲处于等待。整体来看并没有什么有用的信息,堆栈的记录的也是”事后“了。
通过这里也可以基本确定瞬间的某个行为带来高负载,但是立刻又恢复了。 (心里其实也有个猜测,可能存在乐观锁,在高并发场景下导致锁失败疯狂重试,最终也验证是这类问题。)
到这里基本上线索都断了,线上环境也没有更多有用的信息。
为了找到背后的真相,决定尝试在独立的环境中进行压测,尝试复现问题现象。
压测复现
因为是瞬间高负载带来的问题,所以只需要模拟服务实例高负载。
果不其然,压测后同样出现了”同款“问题。

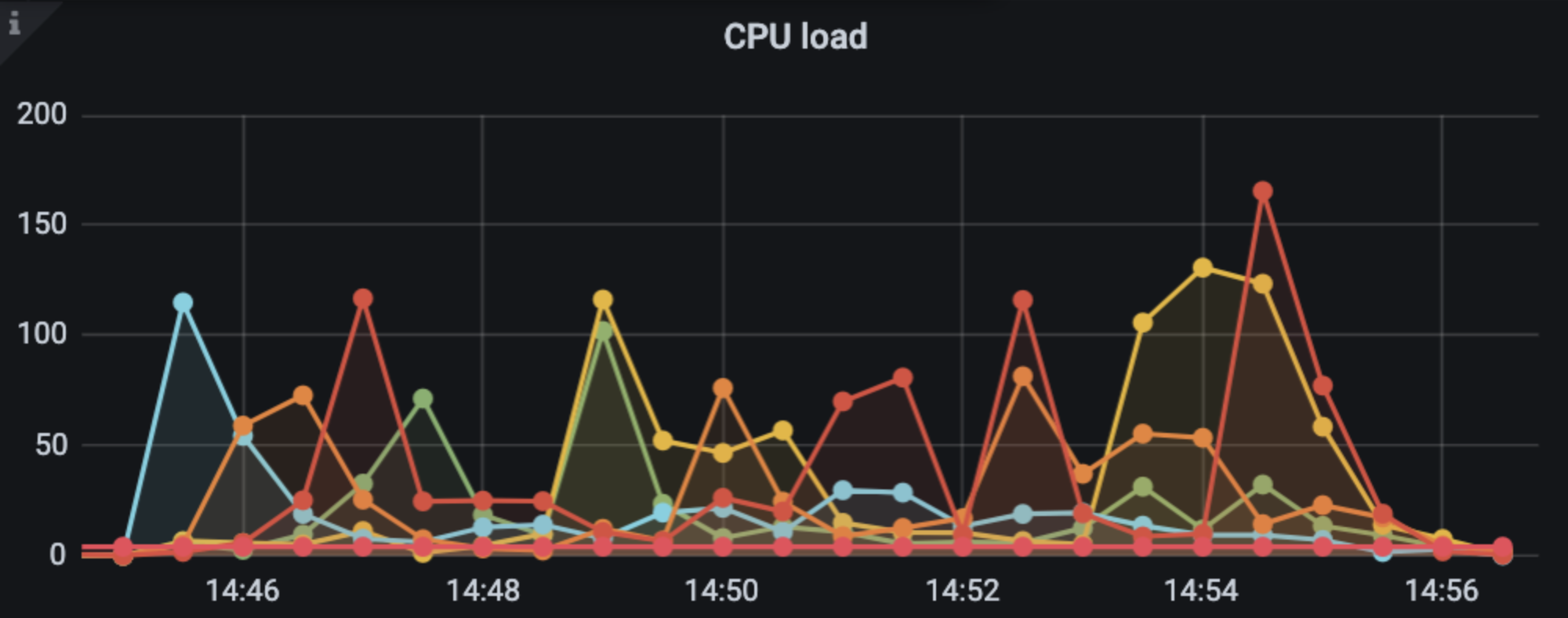
虽然能复现,但由于是瞬间的高并发,通过ONCPU火焰图或者Dubbo线程池的ThreadDump都无法识别某个瞬间的问题。
最终从结果来看,
ONCPU火焰图原本应该是能发现问题的,但是可能由于ByteBuddy做字节码改写后,注入的代码并没有在火焰图记录的堆栈中。
所以我把思路调整了一下,既然99线有尖刺,那就先从99线高的接口调用链路开始查。
链路分析
先从99线高的链路可以追踪,找到对应的慢调用,可以找到这样的一些链路信息:

接口逻辑非常简单,只是去DB查一下数据,但是接口耗时达到6s。
其中,耗时比较长的时间在getConneciton,难道是连接池不够用?
为什么有两个?和我们自定义注入函数和
APM SPAN逻辑有关,实际是对一次获取连接操作记录了两次。

从上图连接池的连接使用及队列等待监控来看,连接数还很充足。
那么为什么会getConnection很久呢?
参与这个过程的耗时,除了获取连接行为本身,还有一个容易被忽略的行为,APM Span的采集,有没有可能是这个原因呢。
真的是APM Agent的问题吗?
想到这里其实自己也不太确定,毕竟APM Agent这些年一直在用,也并没有发现什么问题。
抱着掐指算命试一试的态度,临时把APM Agent关掉,做了一轮压测对比。

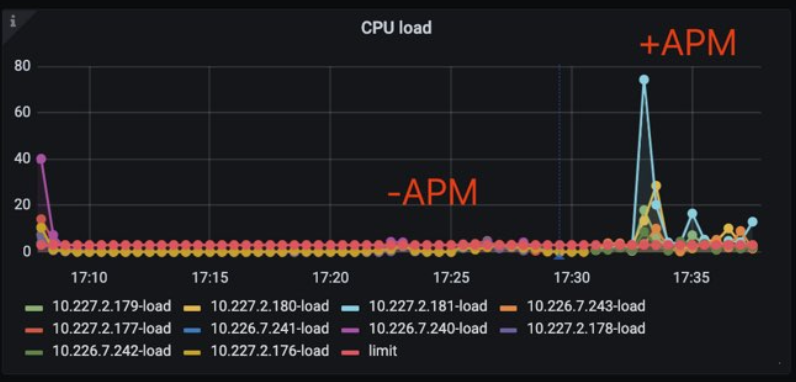
不试不知道,一试就有点蚌埠住了。
移除APM Agent:99线基本稳定在100ms内,Load相对平稳。
携带APM Agent:99线基本在500~750ms,并且Load出现瞬间飙升的情况。

这就基本上可以确实是APM Agent导致的问题了。
根因到底是什么?
查到这里还不够,还要继续分析根本原因是什么。
为了查到根因,去翻了一下Elastic APM和我们自己APM扩展插件的代码,乍看没什么太大问题,但是既然有99线较高的情况,直接trace一把耗时不久知道了。
首先我找到了APM创建Span的方法,通过Arthas追踪该方法耗时,过滤出大于500ms的链路,最终追踪到了下面这个方法。
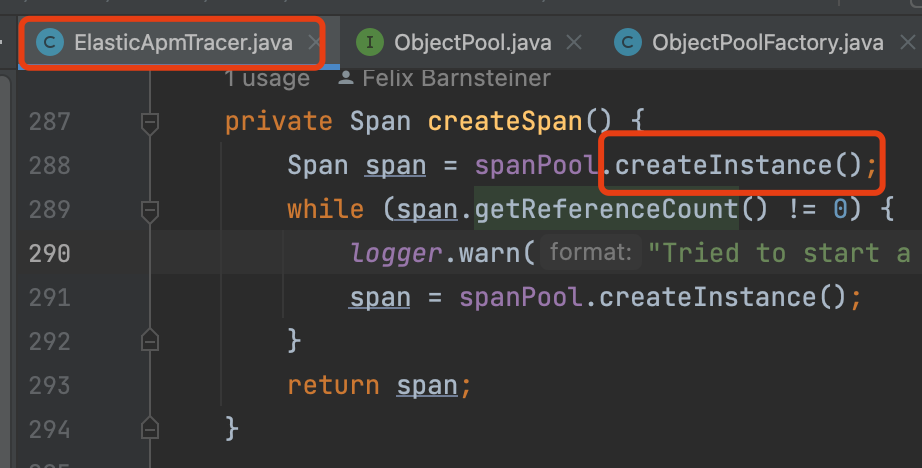

其中,spanPool通过工厂类统一创建,是一个Span对象池,每次需要创建Span时,直接从池中获取,用完归还,避免了对象的频繁创建。
感觉离真相越来越近了,既然用到池化方法进行管理,那么很可能需要解决并发获取和归还的问题,那么这池子是怎样的呢?


而该池子的参数通过ConcurrentQueueSpec指定,是大小限制为capacity,producers和consumers设置为0则意味着该对象池有多个生产者和多个消费者。
而在AtomicQueueFactory工厂类中,通过newQueue创建了一个JCTools的MpmcAtomicArrayQueue。

通过上图可以看到,SpanPool对象池最终是一个MpmcAtomicArrayQueue,那么进一步验证猜想,看看对象获取和归还的逻辑。
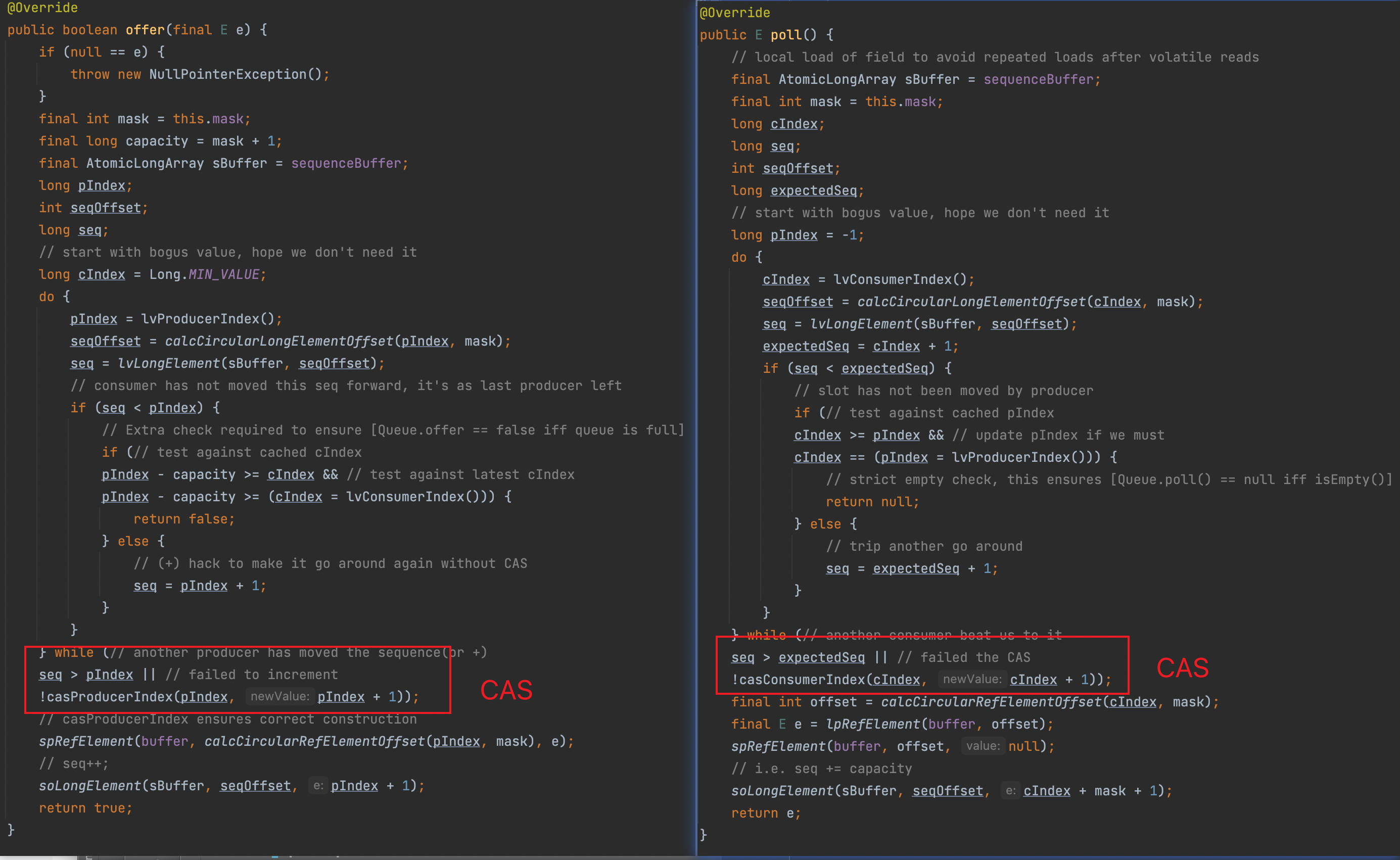
发现获取和归还都是时,都是通过index来判断使用位置,并通过CAS来解决并发问题。
CAS是一种乐观的无锁化设计,适合在冲突并不高的场景下使用,而在高并发的场景下,不断冲突带来不停的自旋,很可能导致瞬间的高负载,有没有可能是这个问题呢?
进一步验证一把,trace一下MpmcAtomicArrayQueue中的方法调用,来判断该CAS是否会带来问题。

可以看到,在极端情况下,该CAS自旋300次+,耗时达到200ms以上。
由此可以判断,在高并发场景里多线程并发创建Span时,需要从MpmcAtomicArrayQueue中获取Span对象,而获取过程中的CAS自旋带来了高负载,导致耗时增加,99线出现尖刺。
看到这里你可能会吐槽Elastic APM真辣鸡,怎么选择了MpmcAtomicArrayQueue这种队列,还用了CAS来实现并发控制。
那么这个MpmcAtomicArrayQueue到底是什么呢?
要了解MpmcAtomicArrayQueue,先来看看JCTools。
JCTools
JCTools是为JVM提供的Java并发工具集,其目的是为弥补当前JDK中缺失的一系列非阻塞并发数据结构。
在传统的多线程场景中,都需要一个可变的共享状态变量作为锁,来保证数据的一致性,也保证数据的变更为外界所知。
但是这个方法存在一些问题:
- 线程需要阻塞并等待获取锁,直到另一个线程结束并释放锁,这会降低程序的并发度;
- 重锁冲突和争夺,会导致JVM需要花费更多的时间处理线程调度、管理锁竞争、队列化管理等待线程;
- 可能的死锁;
- 粗粒度的锁也会导致锁时间提升,降低程序并发度;
面对这个问题,可替代的方法就是采用非阻塞的锁算法,CAS指令就是一种无锁化、非阻塞的lock-free算法。
在我们的案例中,Elastic APM就使用了JCTools所包含的并发队列实现:
1 | |
而这些并发队列底层均是使用Index标记进行队列管理,通过CAS将进行并发控制。
而且使用JCTools并发队列的组件不在少数,Netty、RxJava等均有使用。
根因验证
综上所述,基本可以确定MpmcAtomicArrayQueue的CAS会带来性能问题,但是怎么验证我们发现的现象就是该问题导致的呢?
有方法~,因为出现自旋比较严重的场景是在取Span的poll()方法上,那么可以临时切换成MpscLinkedAtomicQueue。
MpscLinkedAtomicQueue是一个有界的多生产者、单消费者队列,所以在poll()的时候并不会进行并发控制,通过增加JVM参数-Delastic.apm.max_queue_size=-1可以进行切换。
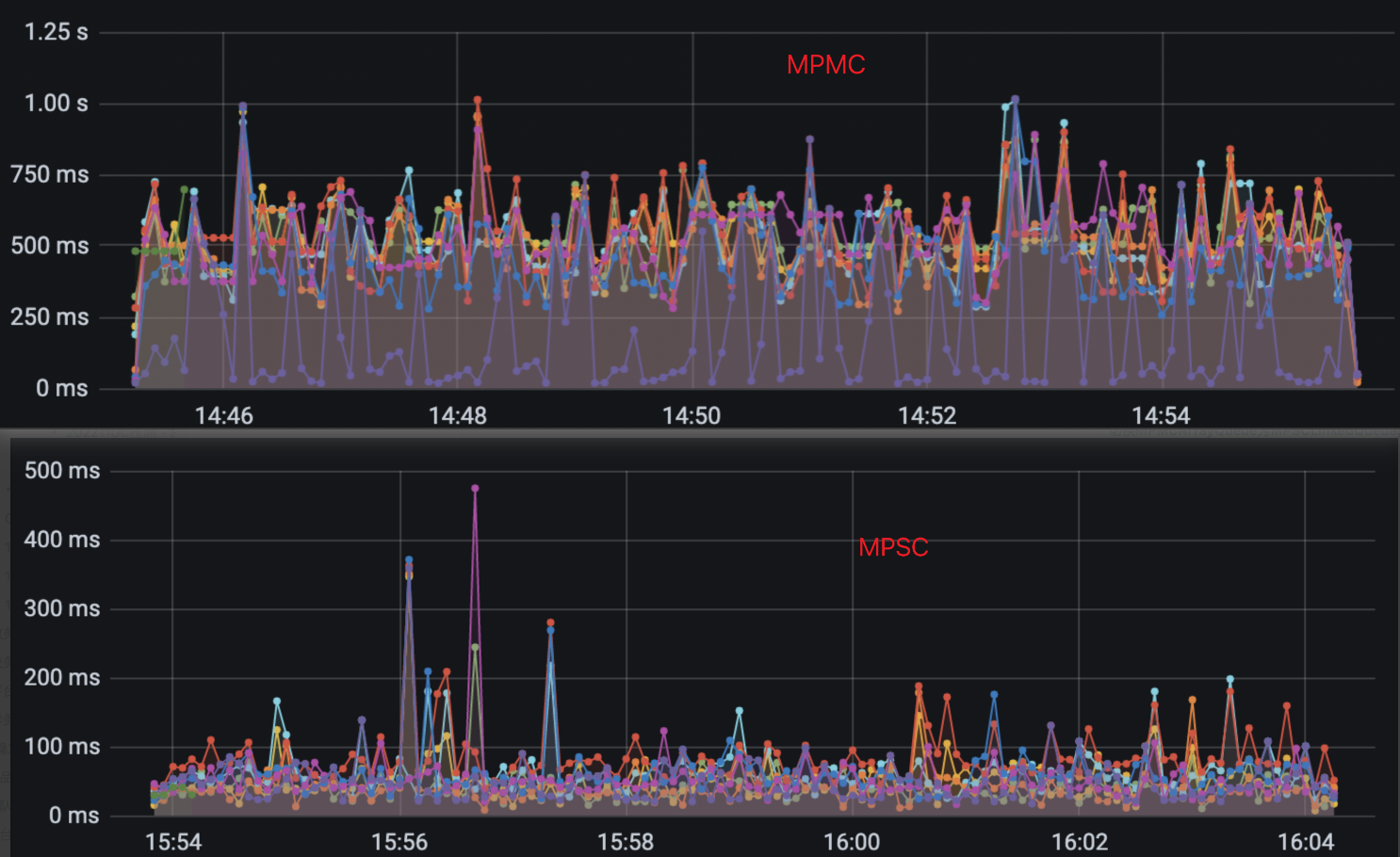
可以看到换成MpscLinkedAtomicQueue后,服务99线也恢复正常,证明该问题是由MpmcAtomicArrayQueue的CAS锁导致。
解决方案
从根因来看,是高并发场景下频繁申请Span,导致从对象池获取Span时,CAS不断冲突引发负载过高。
但这里如果不使用无锁化设计,采用锁进行并发控制,会大大降低程序并发度,那有什么更好的方法呢?
细细想一想,有没有相类似的场景呢?
答案当然是有的,
(1)JVM为了解决所有线程在堆上分配空间的并发性能问题,使用了TLAB(Thread Local Allocation Buffer),每个线程独享一块空间,用于对象分配;
(2)在资源分配的场景中,为了解决资源频繁申请的问题,会采用批量预取+缓存的形式,减少申请次数。
最终我们采用了方案一的实现,每个线程都有一块有限大小的ThreadLocal独享空间,优先从其中获取Span,避免了并发场景下的资源竞争。
采用新方案后的效果如下:
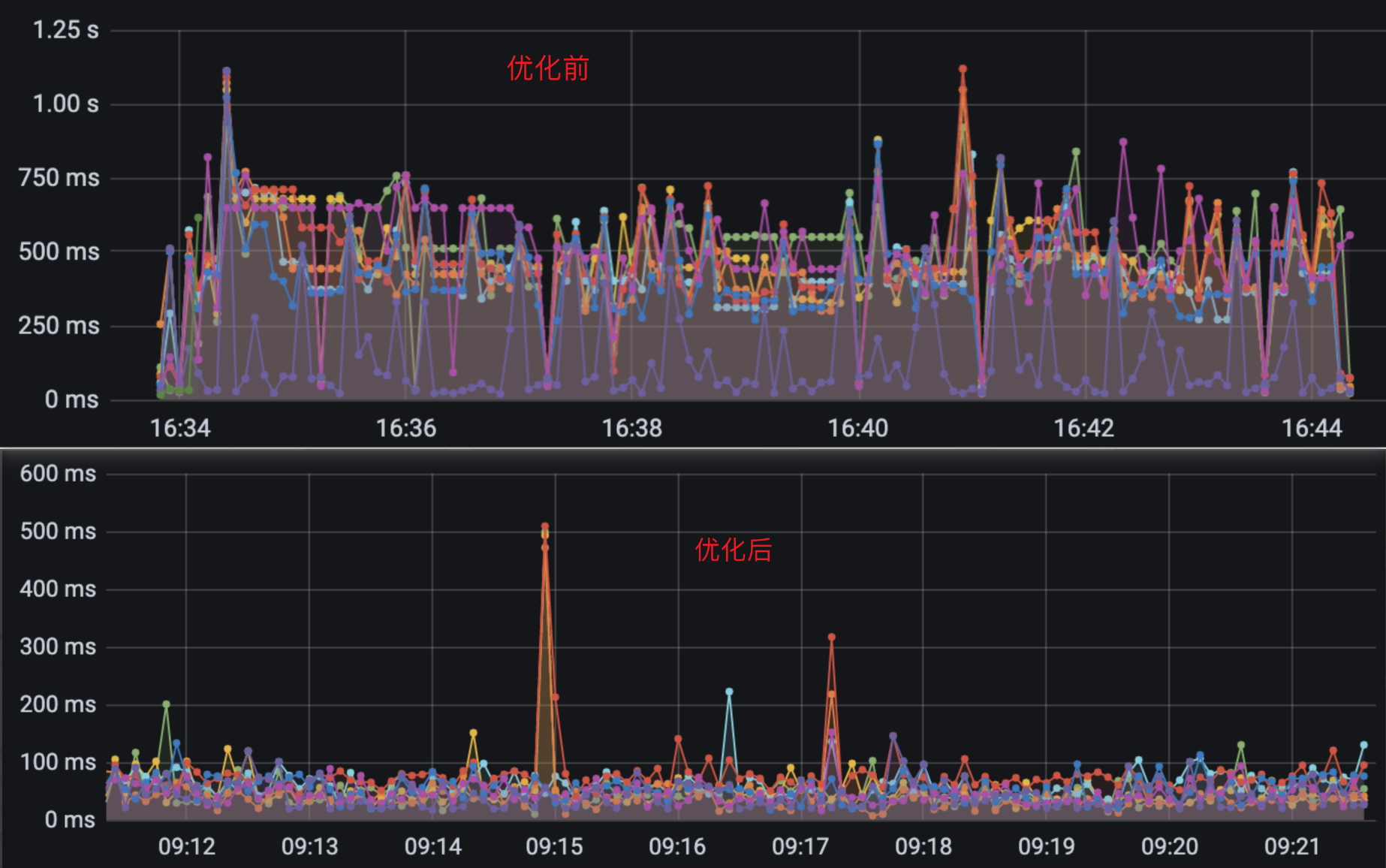
当时也猜测这个方案可能会带来
Agent内存使用上涨,因为每个线程拥有一块独享Span空间。从最终测试的结果上来看,我们有设置ThreadLocal对象池的大小,内存使用上涨不大。
总结
Elastic APM通过使用JCTools的MpmcAtomicArrayQueue进行Span对象池的管理,本意是想通过无锁化的队列来避免锁阻塞及竞争带来的额外开销,用CAS来解决并发控制问题。
但是,这依然没有从根本上解决高并发场景下的资源争夺问题,最终我们通过类似JVM中TLAB的思想进行优化,解决了这个问题。
而Elastic APM本身也有尝试解决这个问题,大佬张师傅在其源码中发现了ObjectPool的ThreadLocal版,类名为ThreadLocalObjectPool,在2018年就已经存在,但从其注释上看,目前仅会用于压测模块中,并未在生产环境使用。
