看回这个公式,
1 | |
生成的目标代码想要被 CPU 执行,就需要使用 CPU 提供的 API,这个 API 就是 CPU 指令集。
常见分类
-
复杂指令集(CISC)
指令数量多且复杂,指令长度不相同,硬件实现复杂指令,属于复杂指令集的处理器包括x86、x86_64等 -
精简指令集(RISC) 指令少且简单,指令等长,编译器进行指令组合完成复杂操作,属于RISC的处理器包括ARM等
两者设计的出发点不同, RISC 使用更简单常用的指令,指令少占用空间小,低复杂度的指令使得 CPU 电路更加简单,功耗和散热低,但是相同的功能需要更多的指令来完成; CISC 提供复杂的指令来优化指令数,以更少的指令实现功能,同时其复杂度也带来的功耗、编译优化等问题。
眼花缭乱的指令集
关于指令集,常常会看到这些关键字:
1 | |
简单来看可以只分出两类,基础运算指令集和扩展指令集
- 基础指令集 (x86、x86_64) 满足 CPU 基础的逻辑控制、数据计算,例如 ADD、DIV、OR、JMP等
- 扩展指令集(AVX、VT-x、AMD-V、SSE) 针对基础指令无法满足或效率低下的场景,提供扩展的指令集来满足特定需求
x86、x86_64、amd64?
x86 是 Intel 设计推出的32位指令集架构,基本早期的 CPU 都是使用和支持的 x86_64 是x86指令集架构的64位扩展,AMD 首先推出的64位指令集以扩展x86,称为amd64
sse、avx?SIMD!
我们在编译或者Linux内核源码中,常常能够看到对SSE、AVX指令集的配置,他们有什么特殊之处呢?两者其实都是 SIMD 思想的实现。
SIMD(Single Instruction Multiple Data,单指令多数据流),使用一条命令操作多个数据,实现对小碎数据的并行操作,属于 CPU 基础指令集一种扩展方式。
举个栗子,以ADD命令为例。正常的过程涉及取指、译码和执行,首先获取到加法指令进行译码,先访问内存,获取第一个操作数;再次访问内存,获取第二个操作数,然后才能进行求和计算。
如果使用支持SIMD型指令集进行操作,CPU 在完成基础的取指、译码后,访问内存获取多个操作数,通过一条CPU指令完成多个操作数计算。
两者逻辑上的对比可以通过下面的图来理解:
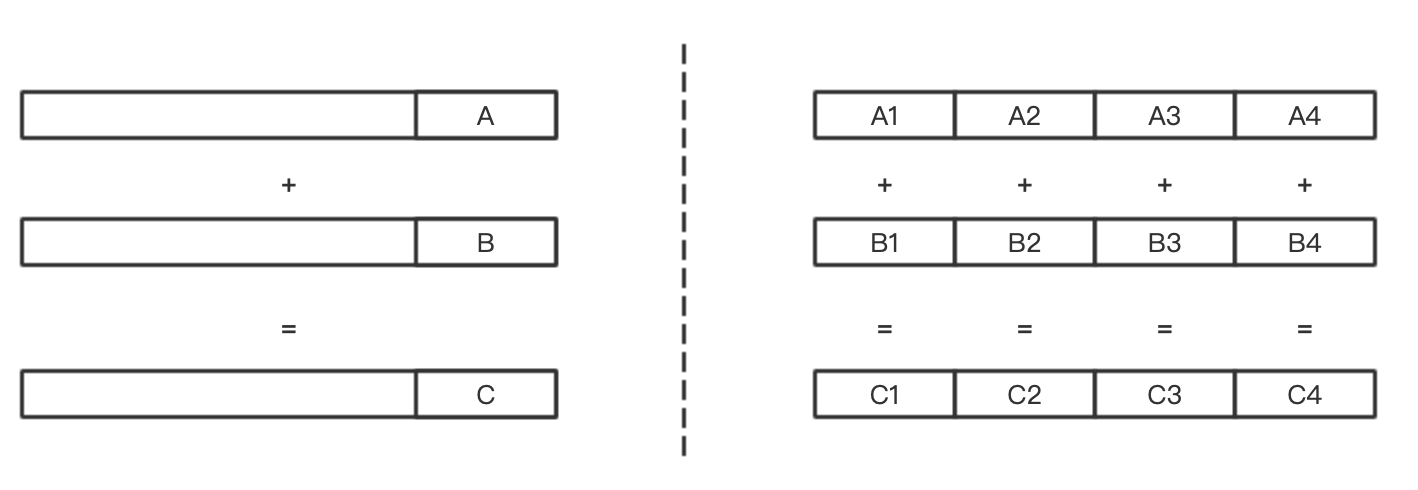
那这个过程为什么可以实现呢,就涉及到几个问题:
32位、64位?
在我们关注操作系统的时候,早些年常常会看到说明系统是32位或者64位,对于64位,大家首先会想到地址空间变大了,能使用大于4GB的内存,而同时它也有另外一层含义,即 CPU 一次处理的数据字长,从32位到64位,单次处理的字长扩大一倍,相应的通用寄存器也扩大一倍。
64位寄存器进行32位运算?
现在的64位 CPU,采用的是64位通用寄存器,那么如果操作一个正常4字节的整形时,只会使用到寄存器的低32位,高32位是不会被使用到的。
没有被使用的高32位就这么浪费了吗?
逻辑上是可以利用上的。举个栗子,如果指令是做加法,那么低32位和高32位逻辑上是可以分开同时计算的,这就是 SIMD 技术的计算方式。
寄存器只有64位?
要实现并行操作,会遇到一个问题,单个操作数最多是可以达到64bit,但是寄存器也只有64bit,怎么解决呢?答案也很简单,更大更宽的寄存器。
怎么告诉CPU进行并行操作?
基础指令集并不支持这样的并行操作,那么就需要给出新的扩展指令集来支持这类操作。
其实通过上面几个问题,基本可以理解SIMD技术的思想,就是使用更大的寄存器,并划分成多段使用,同时通过扩展指令集来实现并行操作,SSE、AVX就是SIMD技术的具体实现。
SIMD 技术是由 Intel 开创的,在1996年引入了MMX扩展指令集,具备64位的矢量处理能力;后续进一步推出了SSE1、SSE2、SSE3、SSE4,矢量处理能力也从64位扩展到了128位。而在2007年,AMD抢先与Intel推出了SSE5,Intel则在第二年推出了AVX。
SIMD 技术应用
以AVX为例,我们来简单了解一下 SIMD 技术的应用。
要想使用,首先来看看官方文档中对AVX指令集的描述,看看它提供怎样的能力。 (英特尔® 高级矢量扩展指令集简介)
1 | |
除了放宽对齐限制和新的扩展编码方案,其中值得关注的是这两个扩展: (1)更大的 SIMD 寄存器。256位寄存器意味着可以支持4个64bit操作数并行运算,相比于128位的SSE扩大了一倍。 (2)单个指令支持3、4 操作数,且是非破坏性运算。官方的例子是一个很好的说明,原来的累加会利用eax进行add操作,结果放在eax中,这个过程仅支持2个操作数,且原本放入eax的原始操作数会被覆盖。3操作数的非破坏运算指令会使部分场景下的运算指令更小、更快。
通过AVX指令也可以观察到这个扩展相关的定义:
AVX寄存器,YMM0 ~ YMM15
__m256,256 bit 单精度向量 __m256i,256 bit 整型向量 __m256d,256 bit 双精度向量
AVX指令
Intel 官方给出了其支持的所有API指令(Intel® Intrinsics Guide),抽选几个我们来看看:
双精度向量加法,__m256d _mm256_add_pd (__m256d a, __m256d b)
1 | |
高低位赋值,_mm256_storeu2_m128i(__m128i* hiaddr, __m128i* loaddr, __m256i a)
1 | |
通过一个例子,我们也来看看AVX带来的提升。
1 | |
代码逻辑依然简单,首先初始化一个数组a,然后对数组a进行求和,得到的结果如下:

如果使用AVX进行优化,那么代码将改写为:
1 | |
改造后的代码有几个变更:
(1)使用浮点计算代替整型计算
(2)sum类型变化,使用了256bit双精度类型
(3)for循环计算使用AVX命令,先通过_mm256_load_pd进行4个64bit的浮点数字,在通过_mm256_add_pd进行累加
(4)通过_mm256_store_pd从256bit双精度中读出4个64bit的结果,并累加在一起得到最终的结果。
由于这段代码使用了AVX指令,使用gcc编译时,需要带上编译参数-mavx,以在编译过程中支持AVX。编译完成后,执行结果如下:

从结果上可以看到,使用AVX指令进行优化后,耗时是优化前的60%左右。
JVM + SIMD
在 JAVA 中,JVM 实际上是默认开启 SSE 和 AVX 的,在官方文档中有进行描述(The java Command)。
1 | |