临近旺季,对过往的故障进行复盘,发现目前的全链路更多是服务层面的异常识别和分析,但是对于更上层业务流量的异常是无法识别到的。
举个栗子,某天运维迁移路由或负载均衡,结果少迁了一个核心服务,外部流量无法正常请求到服务上,此时链路上没有请求,不会有任何告警,业务层面无法快速感知到这类问题,或者只能依靠运维基于域名的流量阈值监控。
因此才想实现一个业务流量的监控,当流量骤升骤降的时候能够主动发现,而基于Flink能比较好的解决数据实时计算、聚合和分析的需求,更快得到监控结果。
整体流程

数据来源
来源数据需要能够真实反应出线上环境的流量变化,并且数据延迟不能太久,否则会直接影响监控的时效性。
在我们的平台中,可选的数据源包括Nginx日志、APM调用拓扑以及业务上报埋点。
其中,
-
Nginx日志,filebeat采集access log,走Kafka写入ElasticSearch,最终需要从ES中获取。这种方案实时性一般(非高峰时段下60s左右数据全部收到),优点是可以利用ES聚合函数进行数据预聚合,但是缺点是需要通过域名+URI映射出对应的服务,且高峰时段数据延迟较久;
-
业务上报埋点,业务HTTP请求主动上报,收集端采集后走Kafka存入大数据分析平台,需要通过Hive读取出来。方案的优点是可以自定义数据含义,不以接口为粒度,缺点是业务侵入式;
-
APM调用拓扑,APM字节码无侵入式注入,自动采集上报接口数据,收集端采集后走Kafka写入ElasticSearch,该方案最大的优点是业务无侵入,通过APM可以直接识别服务,并且包含流量来源,缺点是agent端数据10s聚合一次,且数据发送时间取决于发送策略(超时或队列满),实时性不算太高。
在三种方案中,我选择了使用APM调用拓扑,原因主要是APM数据已经预聚合,需要处理的数据量小,同时延迟相对稳定(60s内),能够直接识别流量服务。
同时还有一些其他的好处,能够标识流量来源、异常流量、时延流量,辅助做异常判断。
数据聚合
由于APM数据是10s的预聚合数据,单批的数据时间跨度太小,容易带来误判。
因此,这里我设置了一个1min的滚动聚合窗口,会聚合同一分钟内的数据,之后的风险及异常检测都是以1分钟为粒度进行检测判断。
数据时间及WaterMark
作为数据流的入口,选择以事件时间(Event Time)而非处理时间,并以该时间更新WaterMark。
APM的数据里包含了原始数据的采集时间,由于数据来自后端服务,采集时间均是校正统一后的服务器时间,会更加准确、真实。
1 | |
这里只是定义了WaterMark的来源,实际更新还是默认200ms更新一次。
数据延迟时间
前面有提到,APM Agent采集数据的发送时间取决于发送策略,当数据队列满或超过指定时间就会发送。在服务端比较忙时,队列快速集满就发送;而在服务端闲时,就会等到超时时间(60s)后发送。
为了等到所有数据到达后再关闭窗口,配置了60s的数据延迟时间。
1 | |
看了下源码,比较有意思的地方是
BoundedOutOfOrdernessWatermarks在定时触发onPeriodicEmit()更新watermark时,会默认减一,表示该事件时间以前的数据都全部到达,而当前时间的时间还可以继续接收。例如,当前基于事件时间更新记录的maxTimestamp为1662510479000,但实际触发WaterMark更新时会设置为1662510478999,表示event_time ≤ 1662510478999的数据已经到了,而1662510479000的数据还未全部到达,仍可以继续接收。
趋势风险检测
通过上一个窗口的聚合,数据都是按1min为粒度的聚合结果,接下来就是通过一个滑动窗口判断每收到的1min数据是否存在异常风险,即对比之前的数据,这1min的流量趋势是否存在明显的上升或者下降。
为什么是滑动窗口
该阶段需要对最近1min的聚合结果进行分析,判断是否存在趋势变化。
而趋势判断需要结合过往一段时间的整体变化趋势进行分析,需要获取到之前的数据,所以我使用了一个10min的滑动窗口进行分析处理。
再看WaterMark
之前我们已经在处理流程中的数据源节点,基于事件时间设置了WaterMark,而下游算子取上游watermark的最小值,也会在相同的时刻出发对应的窗口。
那为什么还要再看WaterMark?
来看这样一个场景:
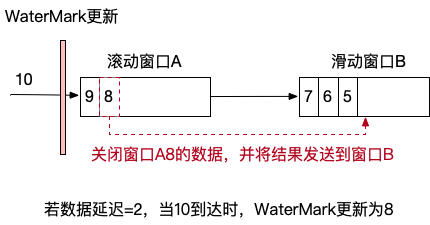
正常情况下,由于10到达且数据延迟=2,此时窗口A的Watermark更新为8。
而窗口B,取上游Watermark的最小值也为8。
Watermark更新后就涉及到窗口激活了,
那么这两个窗口会不会激活,怎么激活,谁先被激活呢?
要想知道答案就要了解窗口划分和激活的逻辑。
- 滚动窗口
滑动窗口比较简单,通过偏移计算当前窗口的位置。
1 | |
这种情况下只会生成一个窗口,窗口激活也只需要判断窗口的start + size ≤ watermark即可。
- 滑动窗口
滑动窗口计算窗口位置及偏移的过程与滚动窗口类似,不同之处在于其需要创建和维护一批窗口的状态。
1 | |
该方法会创建多个窗口,而窗口数量取决于窗口大小及滑动偏移量。
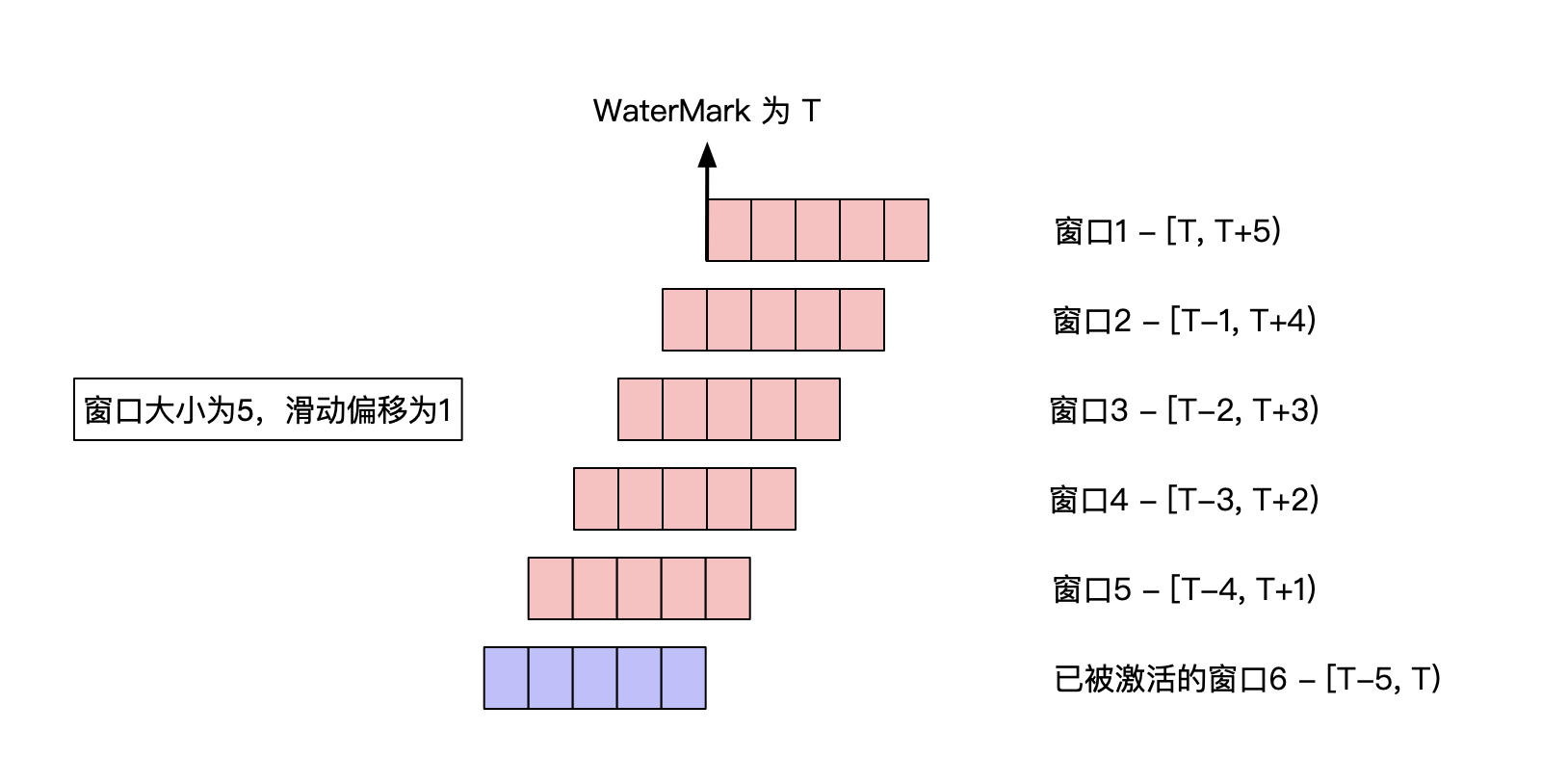
如图可见,对于窗口大小为5,滑动偏移为1的滑动窗口,共有5个窗口未激活,此时这些窗口的windowStart + size ≥ watermark。
而最后一个窗口中,WaterMark已经越过窗口maxOffset,已被激活。
- 谁先激活
回到原始的场景,滚动窗口A及滑动窗口B串联在一起,谁先激活呢?
综上看来,两个窗口的WaterMark都被更新为8,当然是同时激活。
但是,窗口B需要等到窗口A的结果作为输入,
如果两个窗口同时被激活,那么窗口B中会有窗口A的结果吗?
答案是,不确定。
经过测试,在窗口B的计算中,有时能拿到窗口A的结果,有时拿不到,取决于窗口A的计算速度。
那这就会带来一个问题,实际窗口B激活时,数据可能会缺失。
以上面的情况为例,如果窗口A的结果没有进入到窗口B,那么WaterMark(8)激活时,意味着小于等于8的数据已经到了。但是,实际窗口B中并没有8的数据,需要等到9时才能看到8的数据,数据要晚1分钟才能拿到。
怎么办呢?
- 两层WaterMark
为了解决这个数据可能延迟问题,更实时的实现数据分析,我设置了一道新的WaterMark。
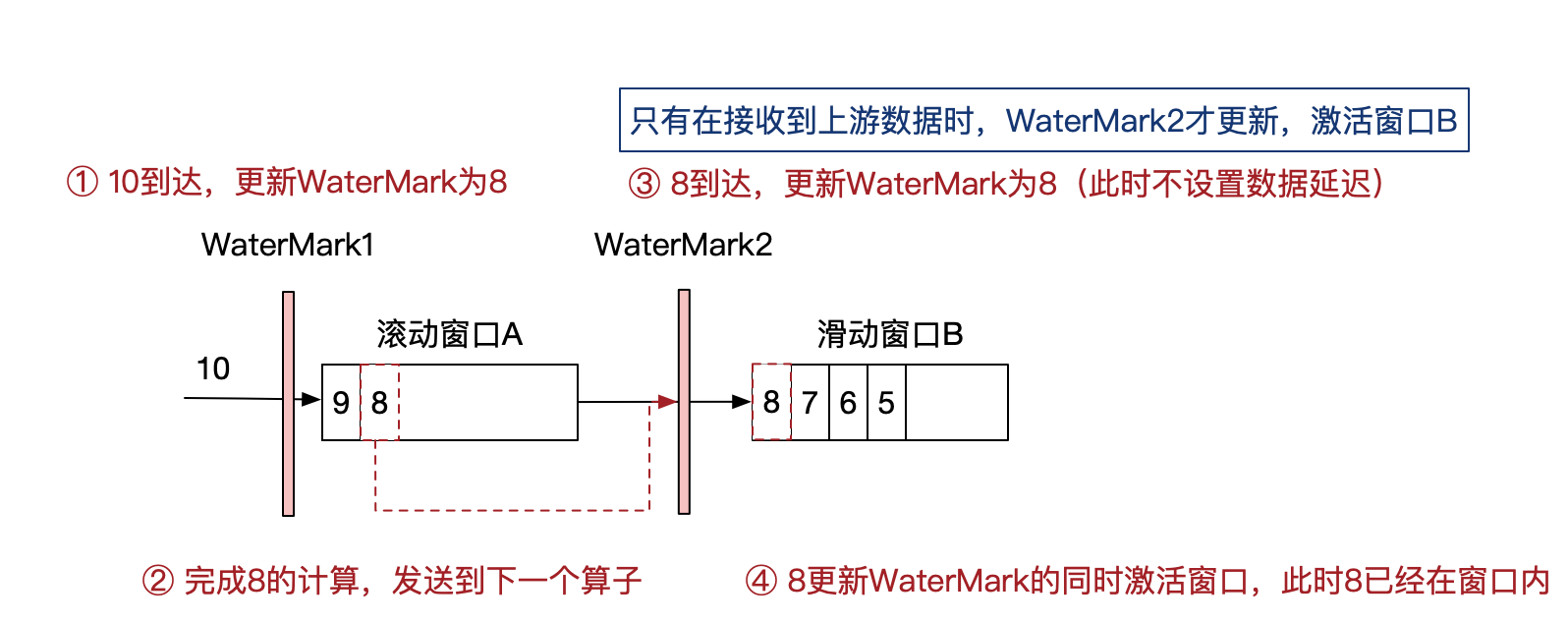
增加了WaterMark2,只有在收到上游数据后,才会更新WaterMark2,并激活窗口B。
通过这样的方式,保证了只有拿到窗口A的输出后,再激活窗口B。
流量趋势分析
解决了数据的问题,再来看如何做流量趋势检测。
流量趋势检测本质上是做时间序列分析,我们期望从中分析流量骤升或者骤降的情况,由于业务即将进入旺季,骤升会带来服务压力短时间内快速增加,影响稳定性;而流量骤降则意味着线上服务处理能力骤降或者链路异常,需要尽快处理避免影响用户。
而流量实际上可以理解为一条时间序列曲线,曲线上的点即为时间点上的请求量总数,要判断趋势变化,就要看曲线是上升还是下降,在视觉上着很好判断,但是转化为数据点进行判断时就需要解决很多问题。
- 如何通过一个个时间点的数据,判断曲线变化趋势?
- 怎样的变化趋势才算是骤升或者骤降?
- 业务流量可能存在正常范围内的抖动升降(非平滑曲线),如何避免误判?
- 业务流程呈现正常的周期性变化,如何避免正常的骤升骤降被识别为异常?
要解决这些问题,有很多分析算法可以实现,有基于统计(3sigma、ewma等)以及AI相关的算法(孤立森林、无监督学习神经网络)等。由于历史数据比较少且剩余的开发时间比较短,最终采用了几种方法融合的方式,使用3sigma + 阈值 + 余弦相似度匹配来共同决策判断趋势变化风险,基于这三个方法,我们逐一来解答上面的问题。
- 如何识别曲线变化趋势
首先,趋势识别不是依靠某个时间点数据来判断的,需要结果过去一段时间的数据来判断当前时间点的趋势。因此在这个阶段的分析上,使用了size为10min、slide为1min的滑动窗口来进行判断,窗口中最近一分钟的数据值就是要进行趋势判断的时间点数据。
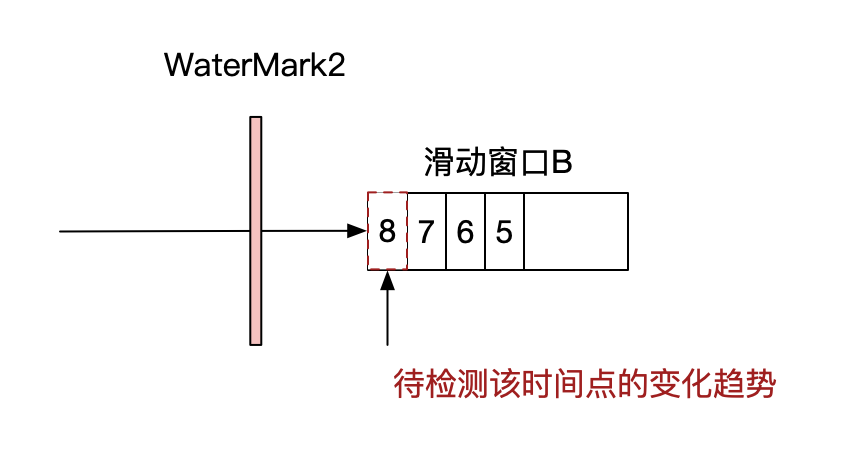
在变化趋势的判断上,通过最近时刻的数据和窗口平均值进行比较。
1 | |
这里可能存在误判,当曲线抖动比较剧烈时,单独使用该规则判断并不准确,需要结合其他规则一起判断才行,仅用于明显趋势变化下的趋势判断。
- 怎样的变化趋势才算是骤升或者骤降?
骤升骤降,意味着数据短时间大幅度变化,所以最简单的方式就是通过流量变化百分比来判断。
那第N分钟的流量变化百分比,是对比哪个时刻的数据得到的呢?
如果仅对比第N-1分钟的数据,那么受到这一分钟流量抖动的影响会很大,带来大量误判。
所以在这里,我们是通过对比[N-9, N-1]的平均流量来判断第N分钟的流量变化
1 | |
同时,这也带来了一个新的问题,
流量变化比例超过多少时可以判定为异常呢?
20%的流量变化算多吗?30%呢?
以我们某个线上服务的流量为例,

上图为业务闲时的流量情况,蓝框部分会1min的请求量,红框部分为流量变化比例。由于闲时整体流量较低,少量的流量波动也会带来较高的比例变化,容易带来误判。
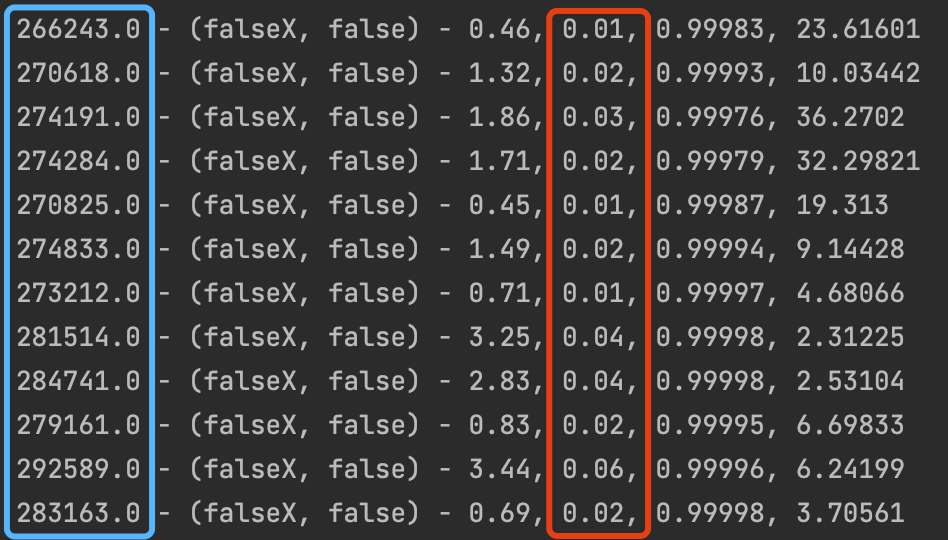
而对比业务高峰时,整体流量基数较大,每分红的流量波动很小,基本不超过5%。
综上所述,我们可以发现两个问题:
(1)基于流量百分比变化阈值的,在流量较小时很容易带来误判。
(2)很难找到一个”万能阈值“来判断业务不同时段的流量变化率是否正常。
在第二个问题上,我们针对业务的高峰、低谷时段分别设置了不同的告警阈值来解决这个问题,例如在低峰时段的告警阈值是50%,高峰时段的告警阈值是20%。
但是,仅依靠这个规则来判断异常流量还远远不够,在流量抖动比较频繁或者流量相对较小的业务服务上检测时,会带来大量误判。
要解决这两个问题,
就要结合下面的方法 - 3sigma原则。
- 如何判断流量抖动是否正常
每分钟流量数据生成的曲线并非平滑曲线,而是上下振动的不规则线段。
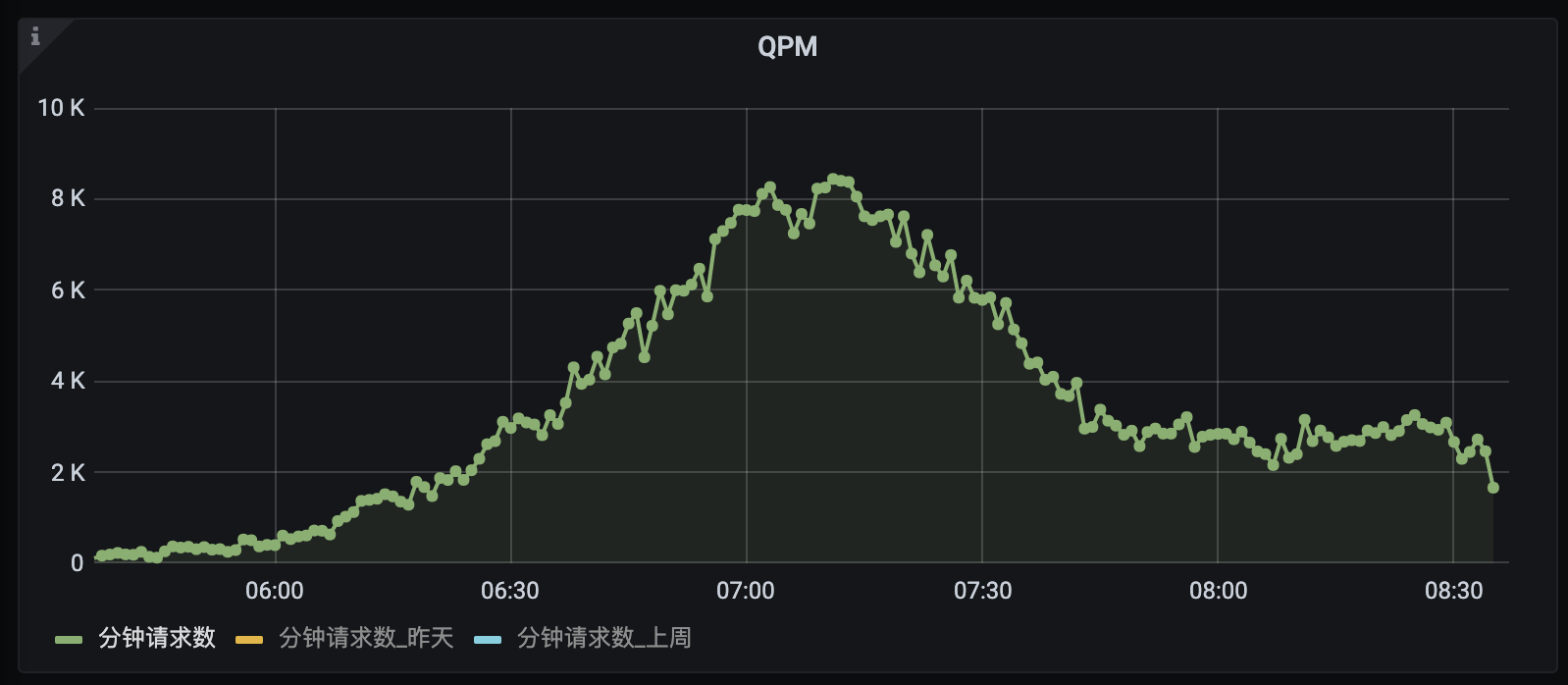
其中也存在不少抖动幅度超过20%的时间点,但是实际上均是正常情况。
那么怎么判断某个时间点的流量抖动是否正常呢?
这里我们主要用到3sigma原则。
3simga原则主要描述数据的偏离程度,判断某个数据点是否为离群值,若数据服从正态分布,则数据偏离1个、2个、3个标准差的概率分别为68.27%、95.45%及99.73%。

在我们的场景中,我们假设时间序列流量数据中,某个时间点的数据是围绕过去时间窗口的平均值上下波动的,以此为前提来看看数据波动的情况。
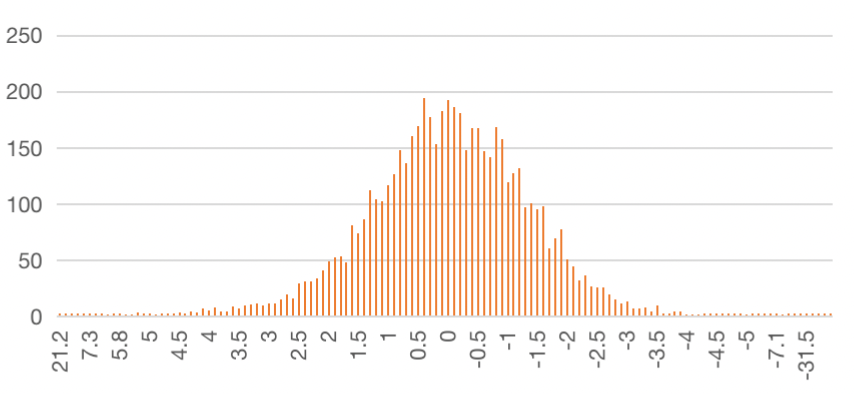
从图中可见,数据偏离的分布也基本符合正态分布,是适合使用3sigma原则的。同时,该正态分布并不标准(略扁一些,尾部更长),通过实际统计得到我们的服务偏差在3个标准差的内数据占比在96%左右。
- 3sigma结合变化阈值进行判断
我们先来看看单独使用流量百分比变化阈值进行检测。

在全天1440个时间数据点中,有67个误报。
再来看引入3sigma后的结果。
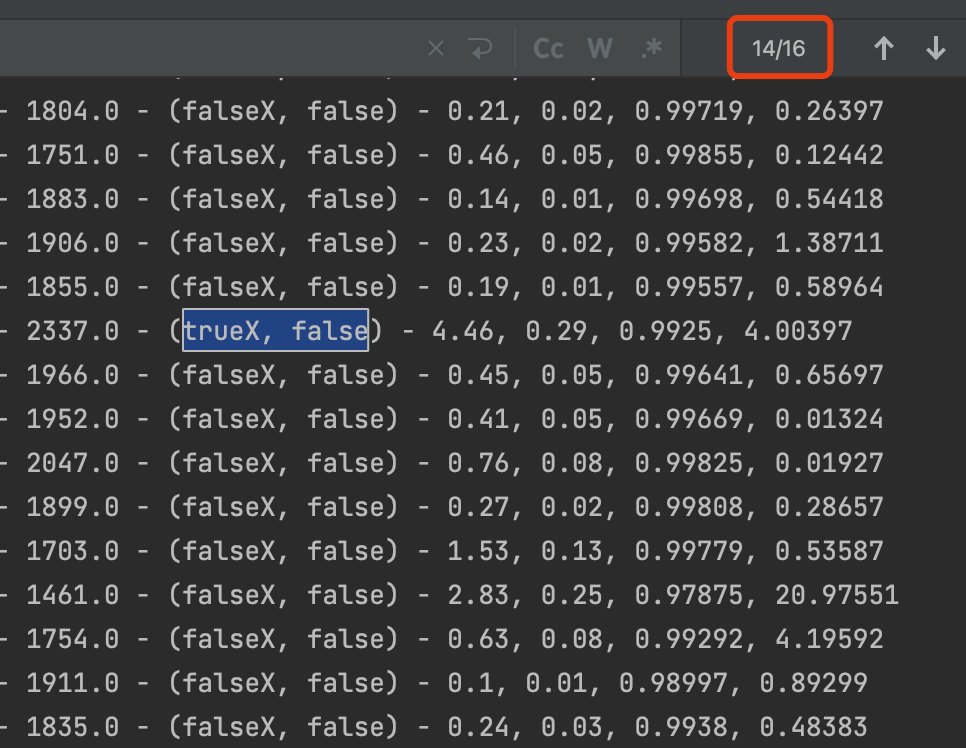
误报数量下降到16个,其中部分数据点的抖动在3个标准差内,识别为正常抖动,因此减少了误报的情况。总体来看,两者结合带来了更好的识别效果。
- 实战效果
来看看两者结合的实际应用情况。
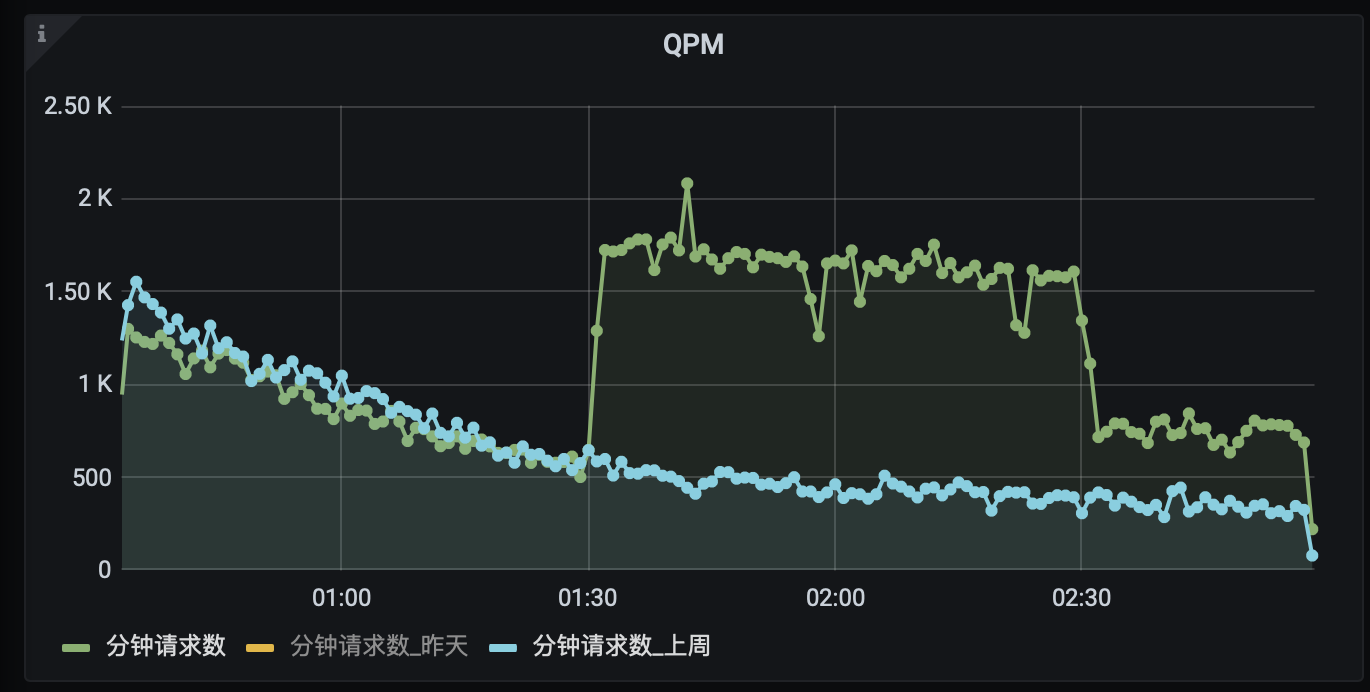
在01:30左右,流量出现了骤升的情况,而告警也相应发出。

其中,流量抖动幅度达到24.49个标准差,同时流量上升191%,出现异常的流量骤升。
- 流量正常的周期性大幅变化如何避免误判
通过上面两个方法已经能够发现流量的骤升骤降,但是一些业务流量可能存在正常的周期性大幅变化。
举个栗子,对于电商业务在每天7点给用户发送通知栏推送,于是大量的用户会收到通知并点击进入应用,带来短时间的流量骤升,这种是属于正常的流量周期性变化。

以上图为例,流量在19:00和19:30都有骤升的情况。
其中,
19:00,流量抖动达到18.11sigma,变化幅度达到36%;
19:30,流量抖动达到18.67sigma,变化幅度达到55%;
但是从图中我们也可以发现,当天的流量曲线与上周的流量曲线是完美重合的,也就意味着这是业务本身的周期性流量变化,属于正常情况,却会被识别为是异常。
那么,要怎么避免这种情况的误判呢?
最直接的方法就是做同比或者环比,发现和上个周期的流量曲线相近,那么就是正常情况。
那么此时问题就发生了变化,我们需要找到一个方法来比较两个时间序列曲线的相似度。
在曲线相似度的比较上,可以理解为两个向量的比较,包含方向和大小,而我们关注的是两条流量曲线的变化方向。
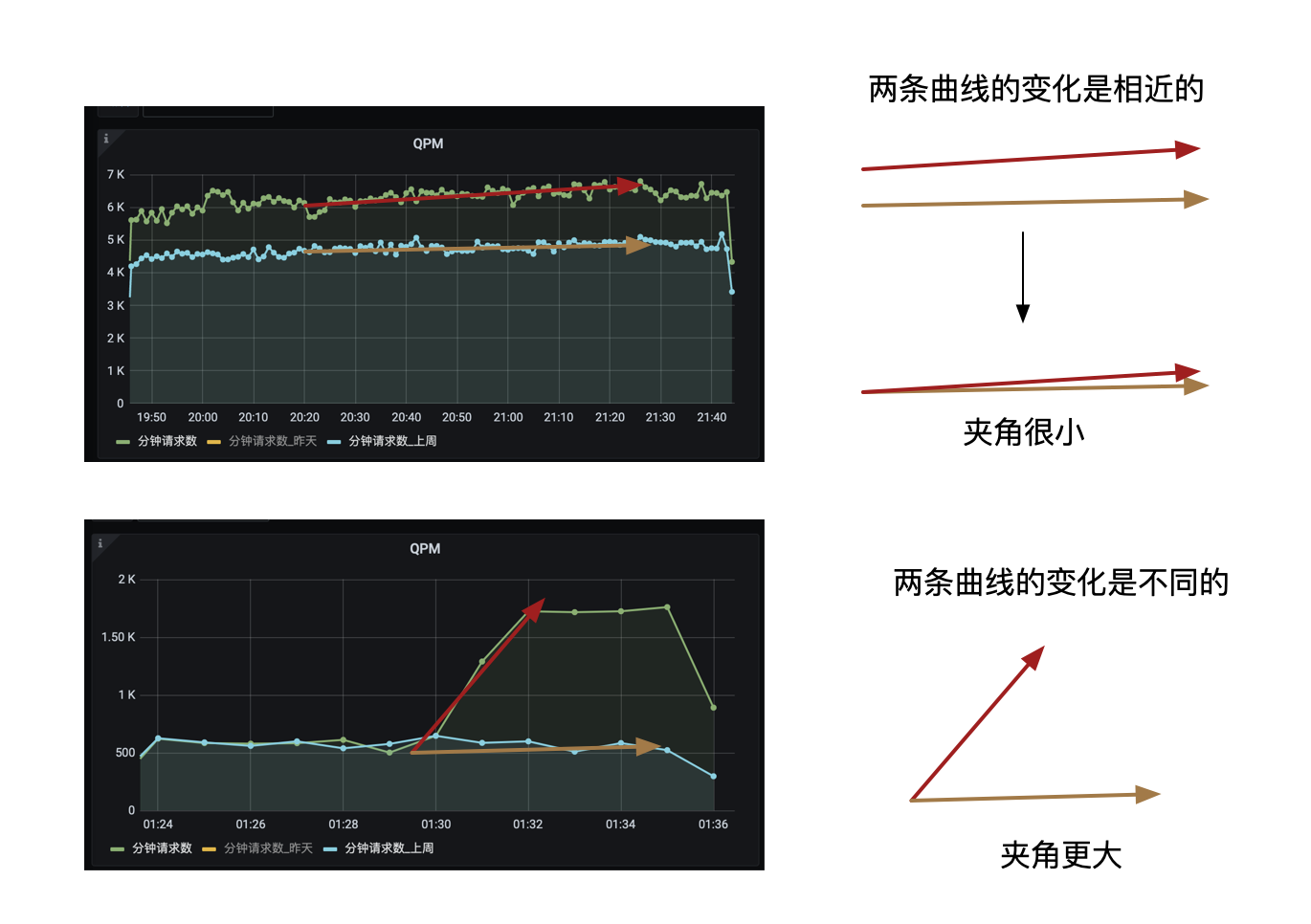
从上图可以看出,两条变化相近的曲线,它们的变化相近,同时变化方向的夹角也更小。
因此,最终我们选择了余弦相似度算法。

算法结果区间在[-1,1]之间,归一化的结果避免了向量模长度带来的影响,而其结果越接近1,代表两条曲线的变化方向越一致。
加上该方法后,我们再来看看刚才的比对情况。
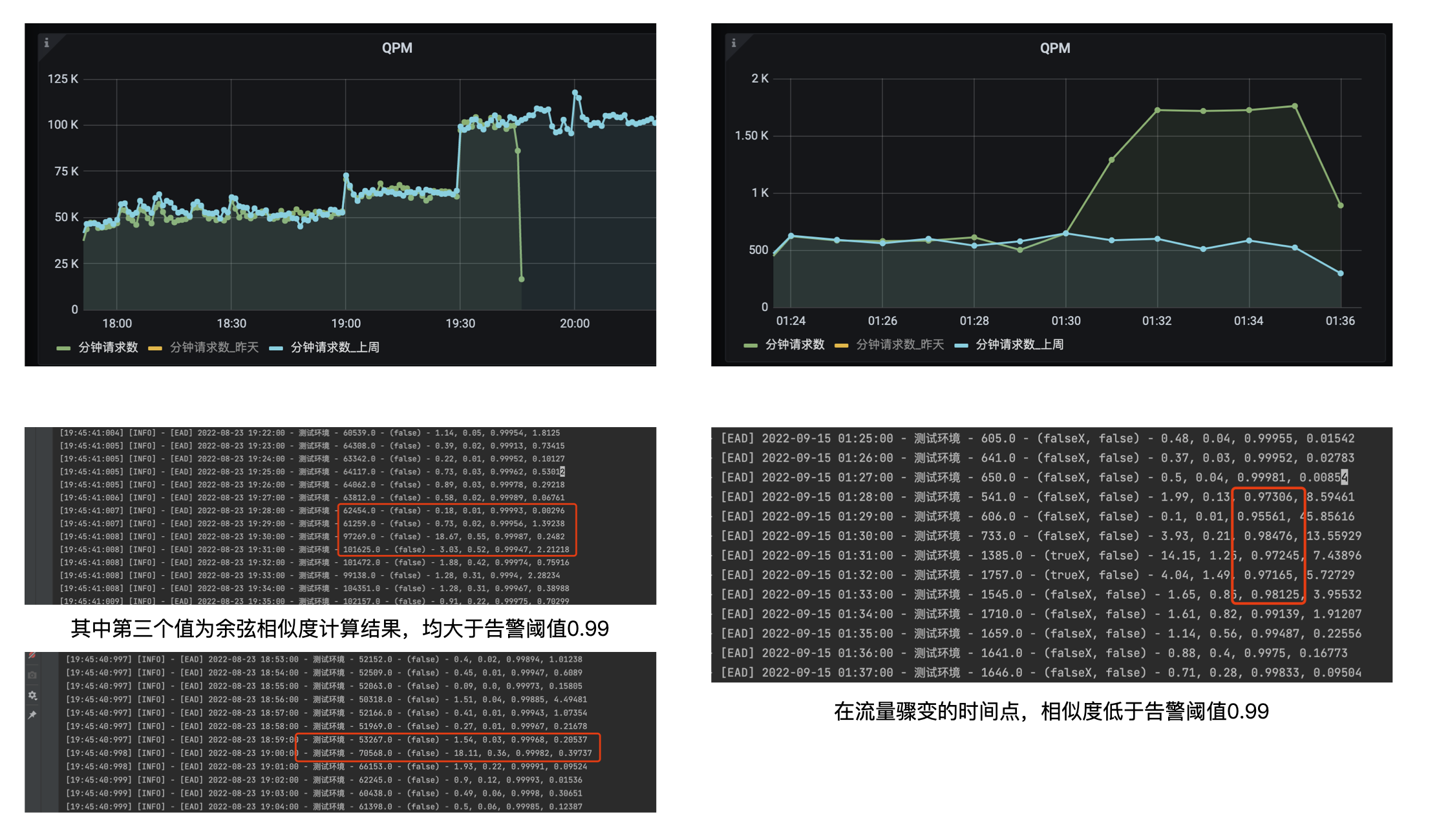
可以看到,对比今日和上周曲线的过程中,变化趋势一致的曲线相似度大于0.99,而不一致的则更低。
通过这个方法,我们可以基于过往的数据来进行比对校正,避免误判。
在实际使用中,我们还使用了移动加权算法,来提升最近时间点数据权重。
因为距离当前时间点越近,其变化方向的影响也越大。
异常判定
上面我们提到了很多方法,用于判断某个时间点的流量是否发生骤变。
那么问题来了,为什么还要一个异常判断的环节?
答案是,线上流量短暂的骤变后快速,是一种比较常见的情况,那么就需要一个机制来判断是否真的发生异常,于是多了一个异常判断的阶段。
这个阶段的逻辑也比较简单,就是用一个大小为3的滑动窗口,判断最终三种的流量是否都处于异常,如果是则判定故障发生。

异常通知
在异常判定发生后,就是告警通知了,这里方式比较多,可以短信、企微、电话等等。
存在的问题和应对策略
冷启动
整个监控流程刚启动的时候,由于窗口中没有过去时间点的数据,所以直接判断或者使用少量的时间点数据进行判断很容易带来误判。
因此,这里我设定了一个冷启动的周期,在积累了5分钟的数据后,再真正进行检测。
窗口中的异常数据影响判断
这里可能存在一种情况,就是窗口里有部分时间点的数据已经异常,会影响最新时间点的流量异常判断。

为了避免异常数据带来的影响,只会使用窗口中的正常数据进行判定。
自适应恢复
如果我们判定流量变化,但是这个变化是服务所能接受的,怎么自适应恢复,接受当前流量而不再标记异常呢?
这里设定当检测窗口里的时间点数据均被标记为异常时,会认为该流量变化已被接受,可以作为正常值进行计算,因此自动加入最新时间点的异常判定,而此时流量已经升高,则会判断最新时间点流量正常,实现自适应恢复。
多服务监控
上面的整个流程是对单个服务流量的监控,而实际我们有非常多的服务,要怎么在这个流程中实现多服务的流量监控呢?
答案也比较简单,使用旁路分支即可,每一个服务都是一个旁路,走相同的检测逻辑。
这样就能实现检测逻辑一直,但是数据流量不同。
窗口中的数据权重
刚才也有提到,在检测窗口中,有使用移动加权算法来提升最近时间点的数据权重,以此来提升这部分数据的影响,提升准确性。
核心指标中的最后一个
有同学可能也会发现截图中的数据其实有四组,但是说明的算法只有三个,那么第四个指标是什么呢?
其实是做了一个相似度校正,引入了两个曲线的间隔区间,如果两个曲线的间隔区间过大,也会认为两个曲线不相似。
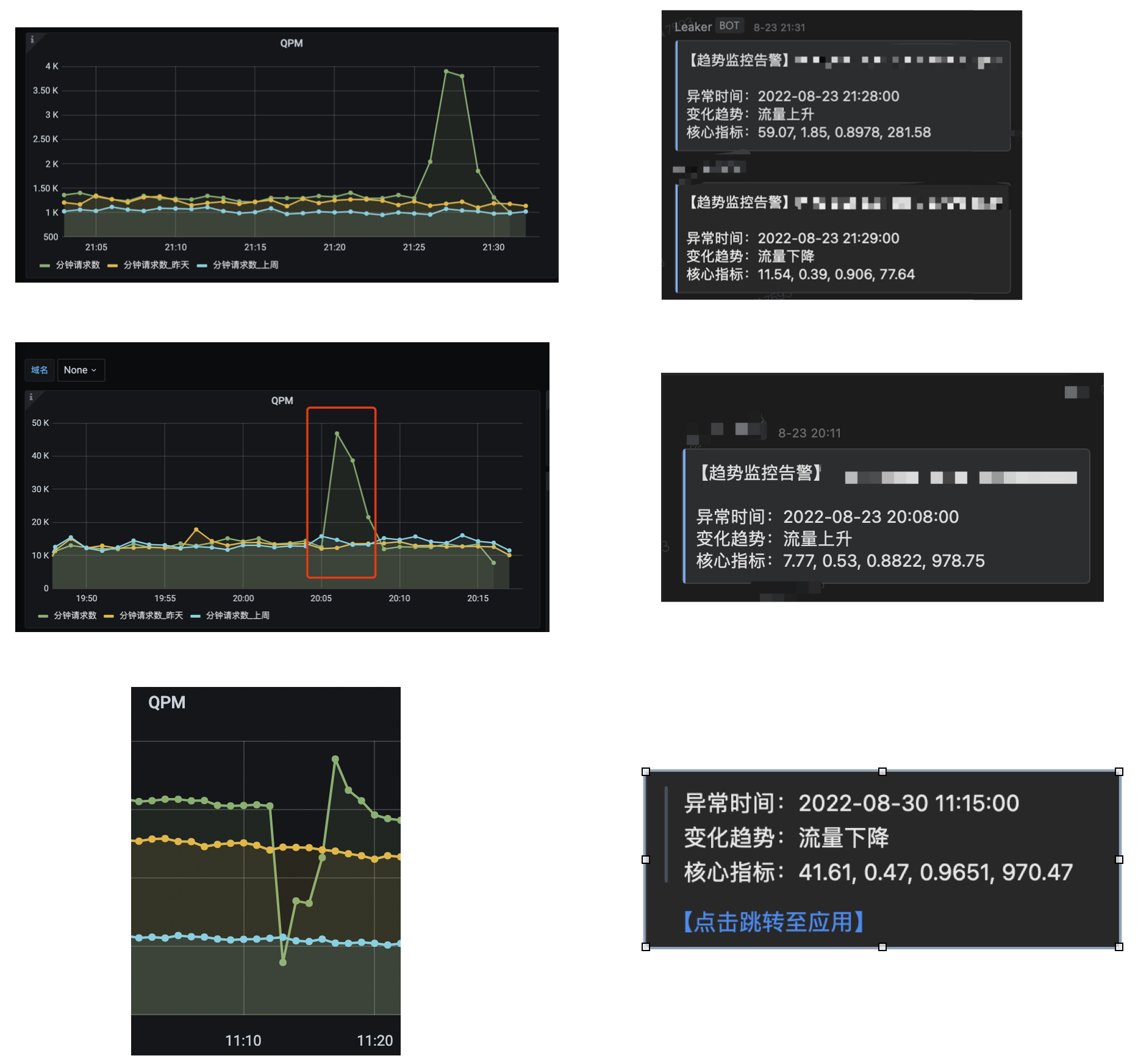
最终效果
放一些线上的效果可以参考。
总结
全篇介绍了一种基于Flink实现的业务流量趋势监控,主要包含两个部分:
- Flink中数据流及算子的设计
- 时间序列异常检查的方法
但是,这些方法并不是最优的,也是当时为了在很短的时间内快速实现做了很多妥协。
- 在数据流及算子的设计上,应该是有机会将处理流程缩减的更短,异常检测时延更短(目前是3分钟),除此之前肯定也更好的方法。
- 这次用到的时间序列异常检测算法其实比较水,中间也有考虑使用孤立森林、Holt-Winters或者基于深度学习的方案,但由于时间有限没有太多时间去尝试,所以才使用了不同简单的方法共同进行分析判断,如果之后有时间会再优化,也期待厉害的算法小伙伴能给出更好的想法。