上一篇里(聊聊我们在Feed流场景下的实践(一)),其实更多的讲到我们基于业务流程和特征,在MySQL下去实现Feed流,也谈到一些问题和分析结果。
这一次想聊聊看我们最终的方案,HBase。
HBase
HBase是开源的非关系型分布式数据库,其具有可伸缩、数据版本化等特点,提供集群式部署,采用计算存储分离的架构设计,能实现对大数据的随机、实时读写,可用于处理billions of rows + millions of columns。
其设计参考了 Google 的 BigTable ,是一个高性能、高可用、面向列的分布式数据库,可用于处理非结构化或半结构化的数据。
从不同的角度来看看HBase
数据存储形式
HBase以数据表的形式存储数据,行键 RowKey 唯一标识一行数据。
这里可以通过一个对比可以来看看数据存储形式。
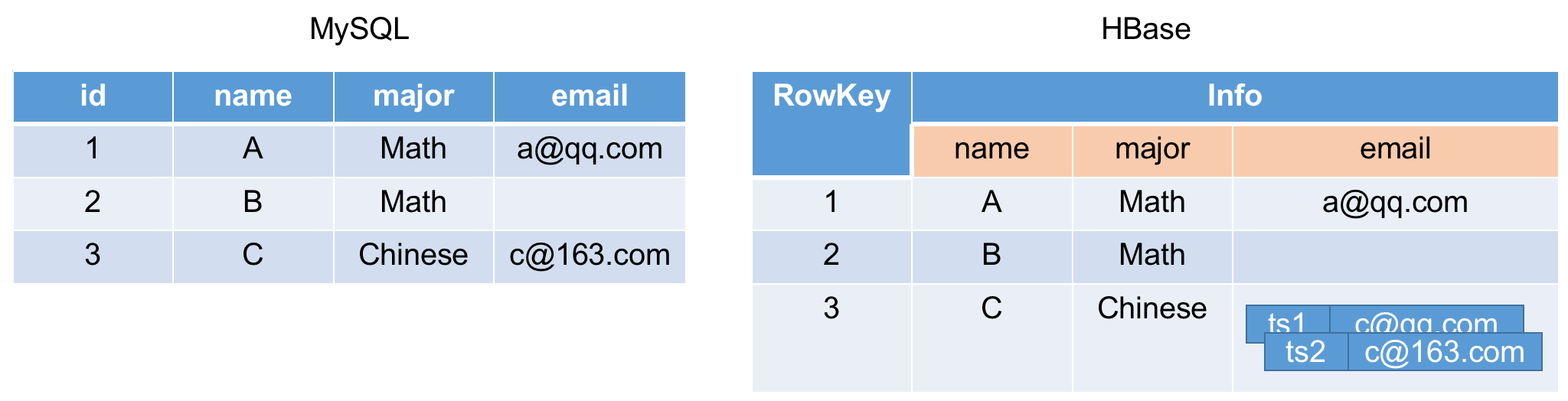
MySQL 和 HBase 中数据的大致对应关系如下:
(仅用于参考和理解,实际还是有很大区别的)
1 | |
逻辑视图
逻辑上看,HBase 数据表由数据行组成,数据行包括行键 RowKey和列族 ColumnFamily组成,其中列族包含一个或多个列限定符 Qualifier。
同样看一个例子。
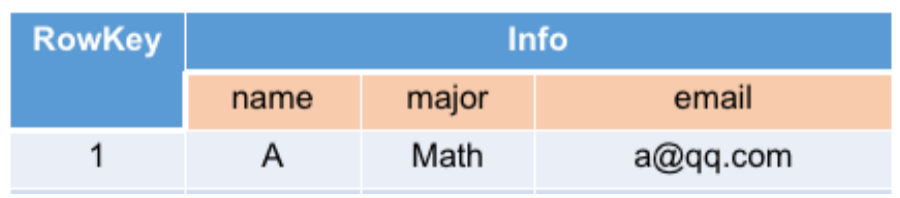
其中记录一行数据,
行键 RowKey = 1
列族 ColumnFamily 仅有 1 个 Info
列限定符 Qualifier 有 3 个,分别为 name 、 major 和 email
而多个数据行组成Region,它是 HBase 存储和负载均衡的最小单元进行按 ASCII 顺序存储,整体结构如下:

随着时间推移,数据行越来越多,Region大小超过hbase.hregion.max.filesize时就会进行分裂:
(源码中,默认配置文件hbase-default.xml中记录的hbase.hregion.max.filesize默认大小是10GB,还是挺大的)

物理视图
从逻辑结构上看,数据表和数据行的关系很简单,其中Region的设计也能很好的支撑分布式存储场景下的数据分片、迁移和备份。接下来,我们从物理视图上,从Region开始进一步分析。
- Region
在Region中,数据并不是按行存储的,而是将数据以按照ColumnFamily存储在多个 Store中,每一个Store对应一个ColumnFamily。
Store的内部结构设计基于LSM Tree,包含MemStore和StoreFile。
当有数据更新时,快速写入处于内存中的MemStore,大小超过阈值时进行落盘,保存为StoreFile(以 HFile 格式进行保存,Hadoop 的二进制格式文件)。内存写入和顺序IO落盘,使其具有非常棒的写入性能,在读取最近更新数据的性能上表现也不错。
(具体可以分析LSM Tree,不细说)

- RegionServer
一张表由多个Region组成,Region分布在不同的RegionServer上,整体结构如下:

Region 不做备份吗?
默认
Region只有一个分片,避免多分片数据同步延迟带来的数据不一致问题,以保证CP中的强C。该值可修改,当有多分片时,副分片仅支持读。
- HLog
HBase 在数据写入时,首先会写入MemStore,这就引入了一个问题,
数据节点突然宕机,内存数据丢失了怎么办?
为了解决这个问题,HBase 引入了 WAL 机制 - HLog,RegionServer收到数据写入或更新请求时,先同步写 HLog,再存入MemStore。当发生灾难需要恢复时,就可以使用 HLog进行重放。
HLog 记录了什么?
包括写入序号、时间、Region、Table、更新内容等重放需要的所有数据。
单个RegionServer只有一个HLog,管理所有Region的变更。

- Master
RegionServer内利用Region实现了对数据的组织和管理,但是RegionServer之间缺少一个方式实现全局数据的管理。
Master则充当了这一角色,主要负责Region分配、RegionServer负载均衡以及元数据等的管理,并通常以多Master集群模式进行部署,以实现高可用。

- ZooKeeper
在分布式架构中,集群节点状态、元数据的管理是非常重要的部分,需要满足数据并发更新、一致性和高可用等。HBase 集群引入了ZooKeeper,进行节点状态、Region和RegionServer元数据等的管理。
整体架构

业务场景
我们可以先通过一个简单对比,来看看HBase与常用的MySQL之间有什么不同。
| HBase | MySQL | |
|---|---|---|
| 部署架构 | Master + DataNode + ZK | 主从、多源、三节点 |
| 引擎结构 | LSM | B+ Tree |
| 优点 | 侧重写(MemStore)、面向列、数据多版本、稀疏数据存储、数据分布式存储 | 读写性能均衡,多结构索引、低延迟 |
| 缺点 | 定期Compaction、LSM多层查询读IO放大、GC延迟尖刺、索引单一等 | 数据量存在瓶颈,性能下降 |
| 运维成本 | 高 | 低 |
| 侧重场景 | 大数据、部分在线业务场景(Feed) | 通用业务 |
可以看出, HBase 对存储介质低敏感,并会对数据进行压缩,存储成本相对可控。同时,支持动态列,数据存储结构也使其适合存储稀疏数据。在大数据及一些特殊场景下更能够发挥其优势,比如用户画像、实时推荐、实时风控、Feed流等。
业务应用 - Feed流
之前有一篇文章,讲述最初我们在Feed流场景下基于MySQL设计的方案以及存在的问题,同时这个方案的问题在于复杂度,维护成本高,且随着用户量增长,MySQL难以面对如此庞大的数据。
所以,最终我们使用了推模式 + HBase。
- RowKey
{user_id}_{time}
用户ID作为前缀,便于快速查找某个用户的Feed流,同时也能解决数据路由的热点问题;随后跟上Feed时间,可以实现以用户为粒度的时间序Feed流。
这里有一个问题,时间降序如何实现?
HBase 的 RowKey 默认按照ASCII排序,而业务场景中需要继续时间降序实现,解决方法是
Long.MAX_VALUE - time来作为时间字段
- 预分区
提前创建了 16 个分区,避免初期Region分裂带来的性能和热点问题。
- 压缩
采用了默认压缩方法Snappy,经测试从 143GB 压缩为 46GB,压缩比大概 30% 左右。
- 测试情况

这是当时测试的情况,16 个分区数据量和读写量相对平均。
- 线上效果
在将功能上线后,花了一些时间做线上数据迁移,并做了流量开关,最终的性能变化可以参考下图:
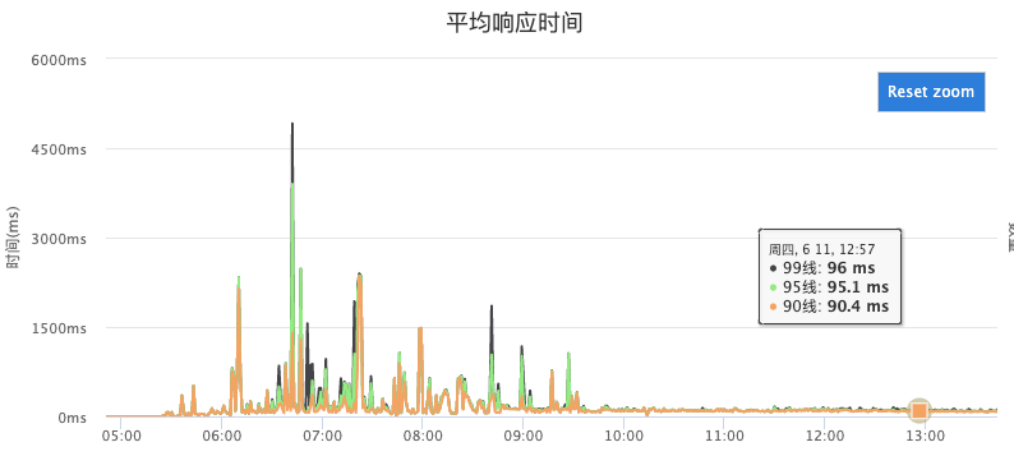
在打开流量开关切入 HBase 后, 99 线大概在 95ms 左右,而之前 99 线在极端场景下已经达到 4.5s ,整体效果还是很明显的。