这次的问题挺有意思的~
项目上会涉及到私有化部署,在边缘侧我们使用K3S(轻量级K8S)进行中间件、存储及服务的部署。
由于大部分业务平台都是直接下沉到边缘,没有做服务优化及裁剪,基本上边缘单机上会有上百个Pod,每次部署的时间都比较长,但是一直也没有太大的问题。
直到有一天,我们在修复和更新某个客户的边缘服务器时,出现了令人费解的异常。
问题现象和原因
在批量更新服务的过程中,部分服务在启动时出现了下面异常:

从结论上来看,只是域名解析异常,首先想到的是CoreDNS,但是发现CoreDNS是正常的。
当我们登录到容器里尝试dig一把时,也在不同的容器中出现了下面不同的现象。
(1)部分容器内,域名正常解析
(2)部分容器内,域名解析失败
(3)还有一批容器,刚进入时解析异常,隔一段时间后正常解析
这就让我们有点抓瞎,排查了一整天都没有思路,而客户那一层也在不断追问进度。
直到半夜,实在没想法的我们,找来了运维大佬,直接一语道破其中的问题:
1 | |
抱着试一试的态度,我们调整了相关参数后,问题果然解决了。
这就很让人费解了,DNS解析异常为什么会和ARP缓存有关?
让我们一步一步来拆解和还原整个问题。
问题分析
要了解这个问题的原貌,首先需要直到边缘服务器网络。
K3S属于轻量级的K8S,我们先从K8S的网络模型开始说起。
K8S容器网络模型
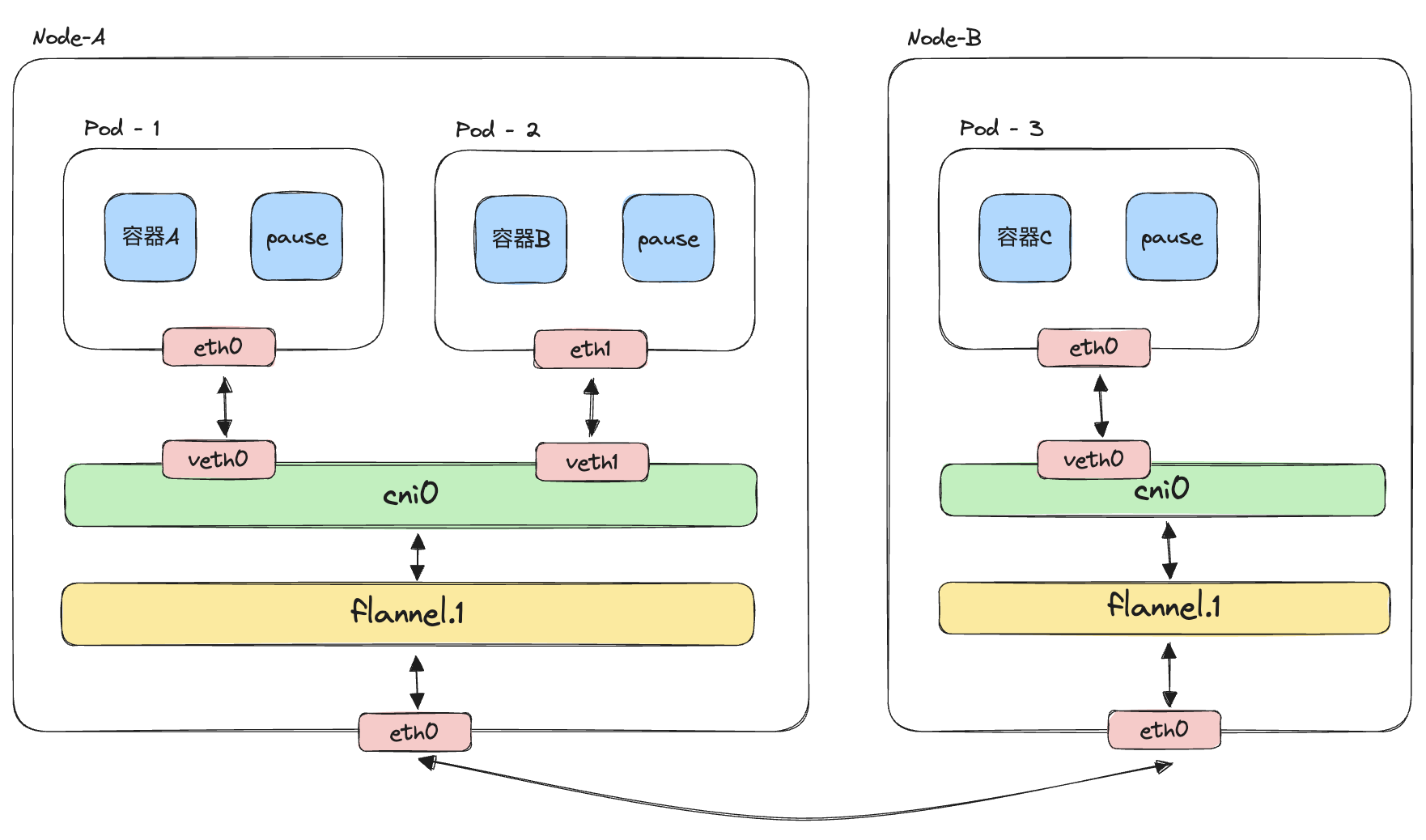
在该网络模型中,
(1)同Pod内的容器通过loopback环回接口通信;
(2)同节点内的不同Pod,通过构建veth与网桥cni0连接,实现Pod之间的通信;
(3)不同节点之间,通过flannel构建的vxlan设备,将数据报文进行vxlan封/解包,实现跨节点通信;
1 | |
K8S网络模型下的DNS解析
在我们的场景中,不涉及多节点,网络结构相对简单一些。当在容器中访问某个域名,且本地没有DNS缓存时,就会向DNS服务器请求获取解析的结果。
这样看还是会比较抽象,来看个更具体的例子。
当我们在容器A中首次发起ping baidu.com时,完整的DNS解析及ping过程如下。
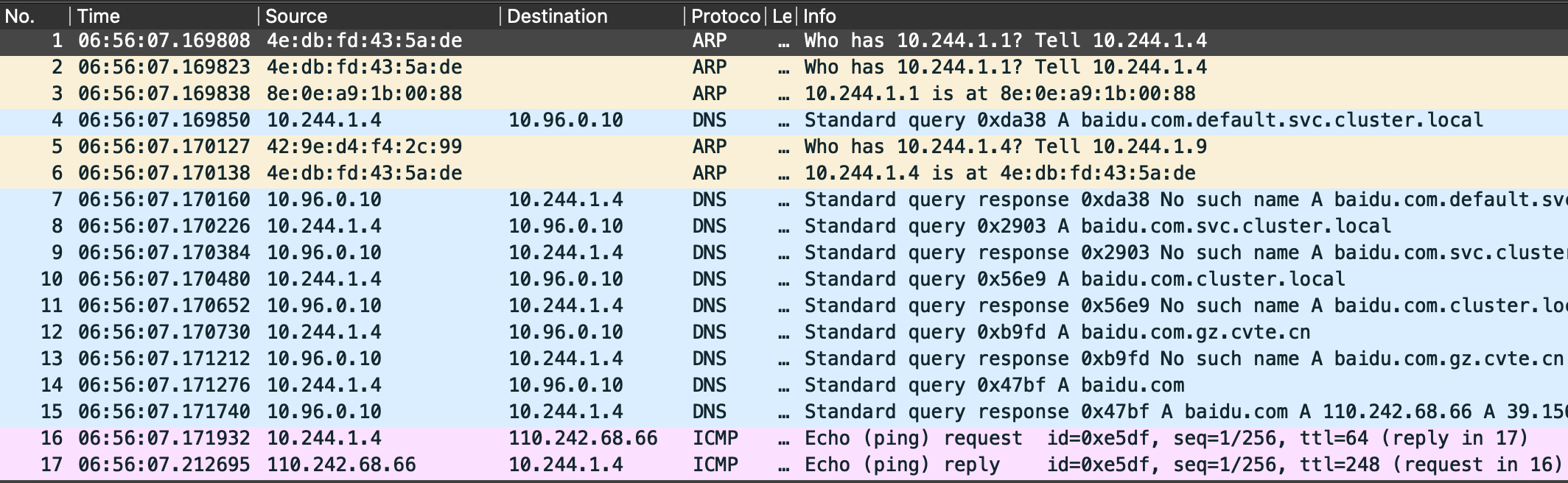
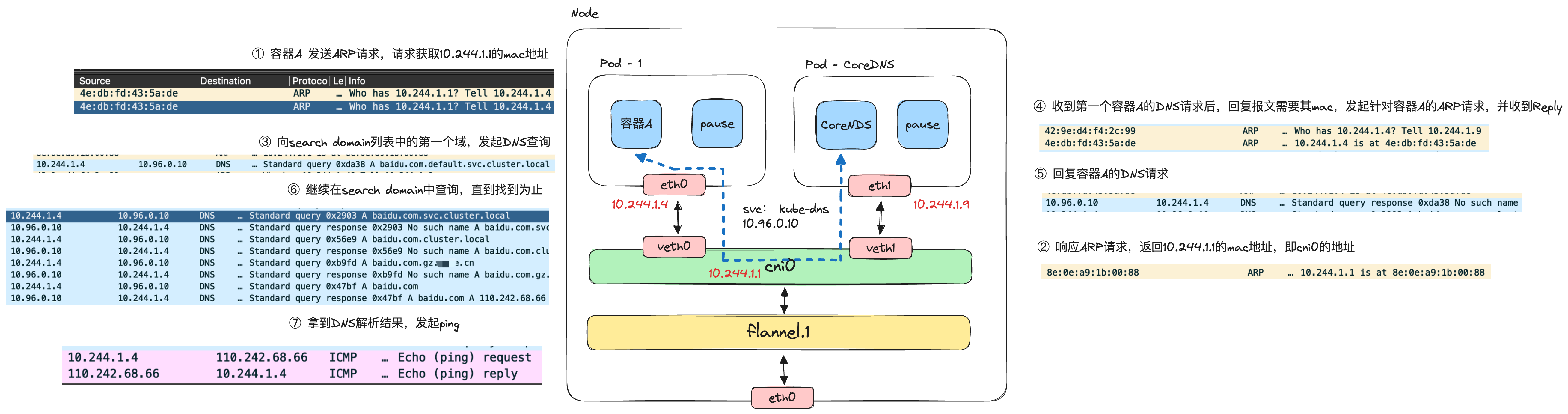
看到这里,你可能就会些疑惑,大家应该能理解ping的过程涉及DNS解析,但是应该会困惑为什么要发ARP请求,且还有两次,我们逐次来看。
- 第一次ARP请求,容器A请求获取
cni0的MAC地址
进行DNS解析,首先看resolv.conf的配置。

对应的nameserver是10.96.0.10,所以发起DNS请求会向该地址查询,但是发起查询前,需要知道发往该地址的包从哪个网口发出。

由此可以判断,default走10.244.1.1,即cni0,因此会先查询其MAC地址,有了第一次ARP请求。
- 第二次ARP请求,CoreDNS请求获取容器A的MAC地址
这个相对好理解,CoreDNS收到容器A的DNS请求,回复时需要容器A对应的MAC地址,因此发送ARP请求查询其MAC。
1 | |
综上所述,在我们的场景中,CoreDNS是正常的,也就意味着不是由DNS服务器导致的问题,那么有没有可能在DNS解析的过程中,由于没有ARP记录、ARP查询请求失败导致DNS解析失败呢?
要验证这个想法,首先我们需要先了解一下ARP缓存。
ARP缓存及GC策略
通常描述的ARP缓存,在Linux内核中被称为neighbor,记录了IP地址对应的MAC地址。
我们一般可以通过ip neigh来查看其内容。

每条记录的基础信息,包含其IP对应的网口、MAC地址及记录状态。
记录的状态包含INCOMPLETE、REACHABLE、STALE、DELAY、PROBE、FAILED中,其状态转换如下(图转),同时定期触发记录GC,回收释放掉无效的记录。
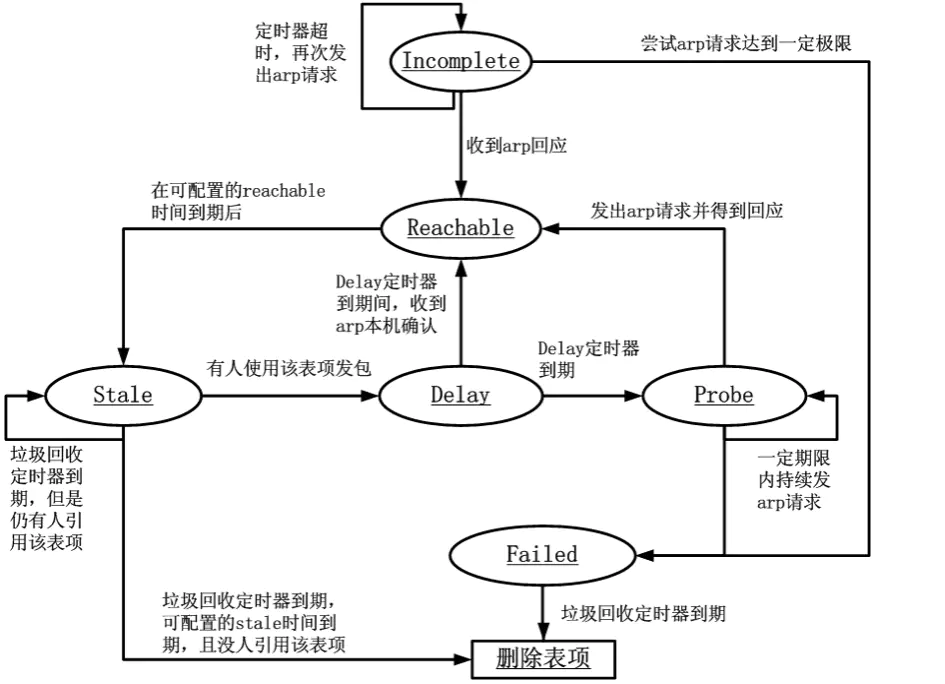
GC有两个场景触发,分别是周期性GC和强制GC,逻辑如下:
周期性GC(net/core/neighbour.c#neigh_periodic_work)
即当ARP记录没有被引用,且非PERMANENT状态,且(记录状态为FAILED或记录距离上一次使用已经超过过期时间),记录会被释放
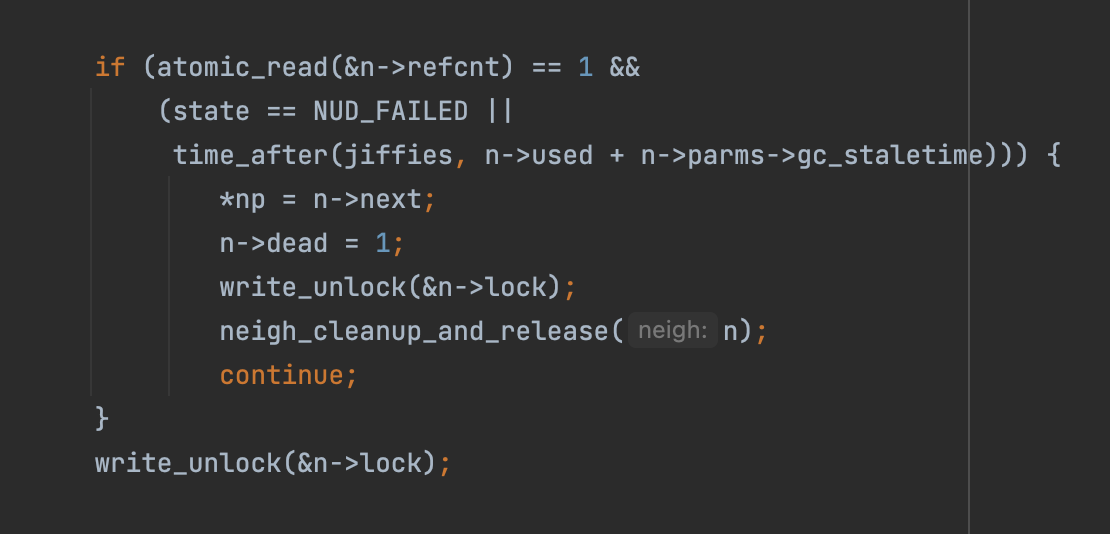
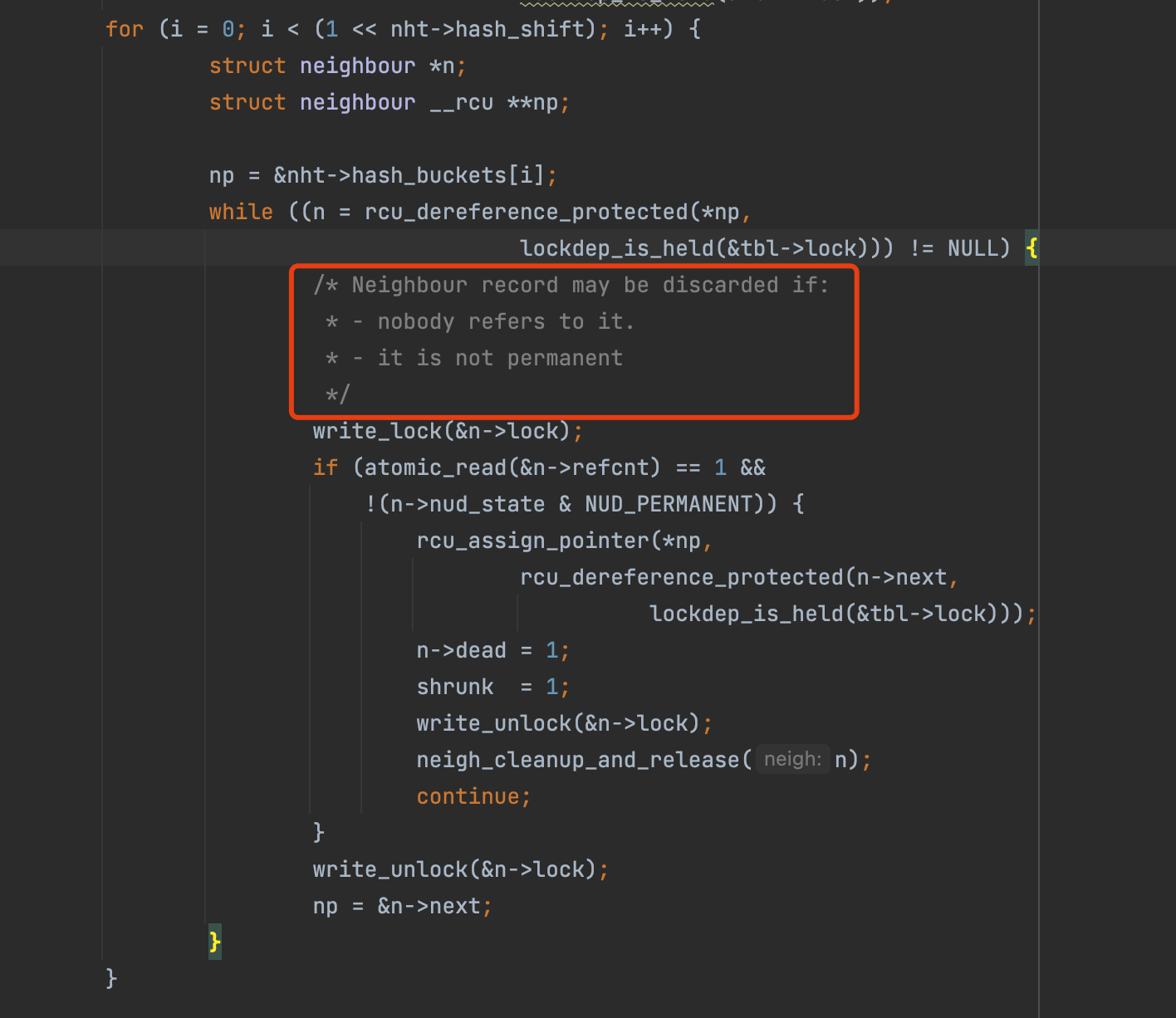
强制GC(net/core/neighbour.c#neigh_forced_gc)
即当ARP记录没有被引用,且非PERMANENT状态时,就会被GC释放掉
关于ARP缓存的GC策略,由内核参数控制:
1 | |
那么,怎样才算ARP缓存满呢?
在net/core/neighbour.c#neigh_alloc中我们可以找到答案。
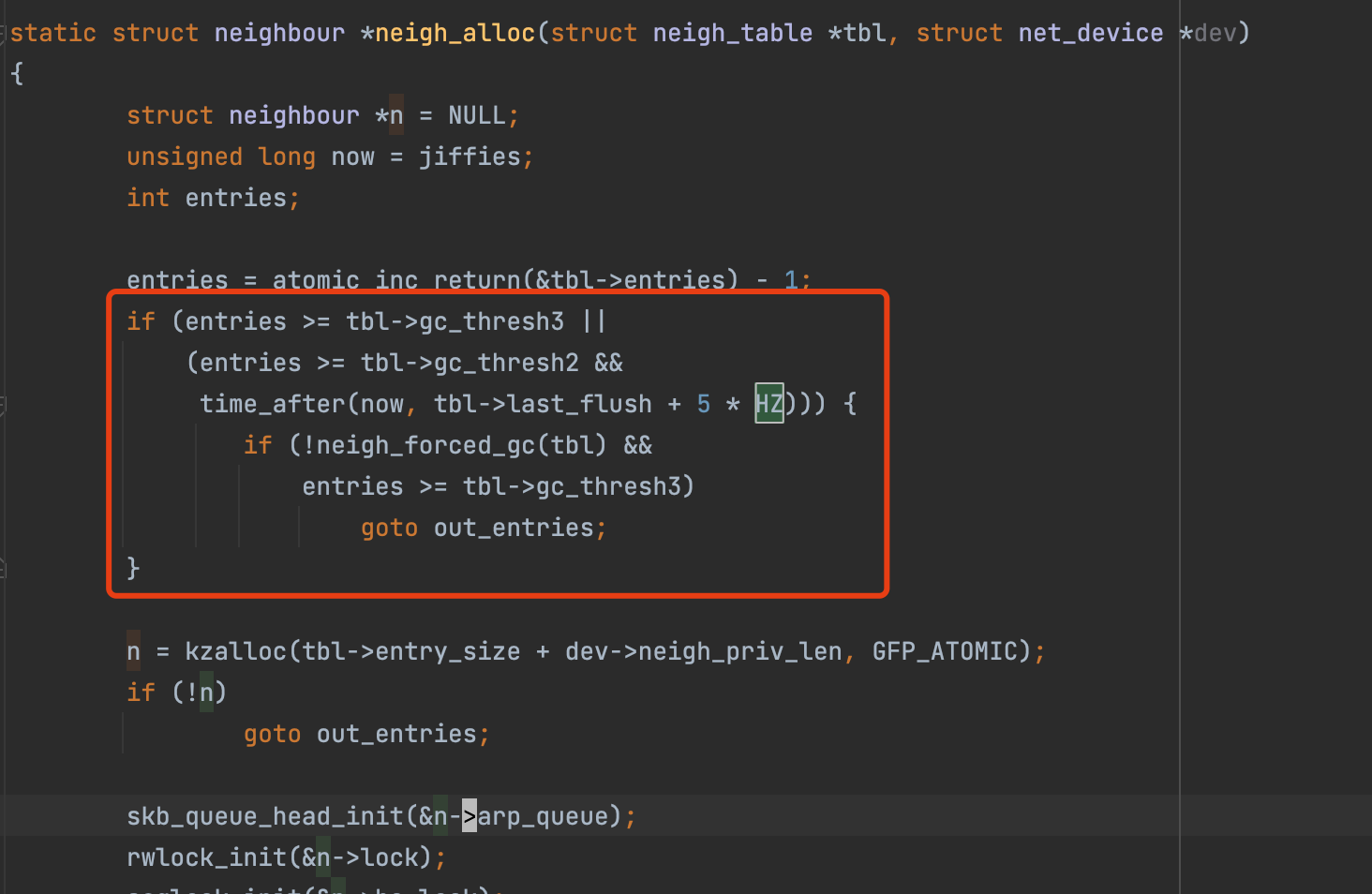
当ARP记录数量超过gc_thresh3,且neigh_forced_gc强制GC后,记录仍然超过gc_thresh3时,会无法创建新的ARP记录。
所以简单理解,gc_thresh3就是上限记录数(不包含PERMANENT记录),
但是这也意味着ARP列表的上限是1024,真的会有那么多的ARP记录吗?
这就涉及到另外一个比较特殊的场景,容器。
NetworkNamespace中的ARP缓存
容器的资源隔离和限制是通过namespace和cgroup实现的,其中network namespace就是用于隔离网络资源。

network namespace提供系统网络资源的隔离,包括网络设备、IPv4及IPv6协议栈、IP路由表、防火墙规则、若干个网络资源目录。在K8S网络模型中,每个Pod有独立的network namespacke,Pod内的容器共享。
既然network namespace隔离,会不会觉得ARP缓存也是独立的?
其实这个network namespace的描述可能有一些不准确,本质上宿主机的资源都是全局的,namespace实现的是资源”可见性”层面的隔离,在对应协议栈中ARP缓存表(neighbour table)其实只有一份。
(协议栈neighbour table源码对应的结构,参考neighbour.h)
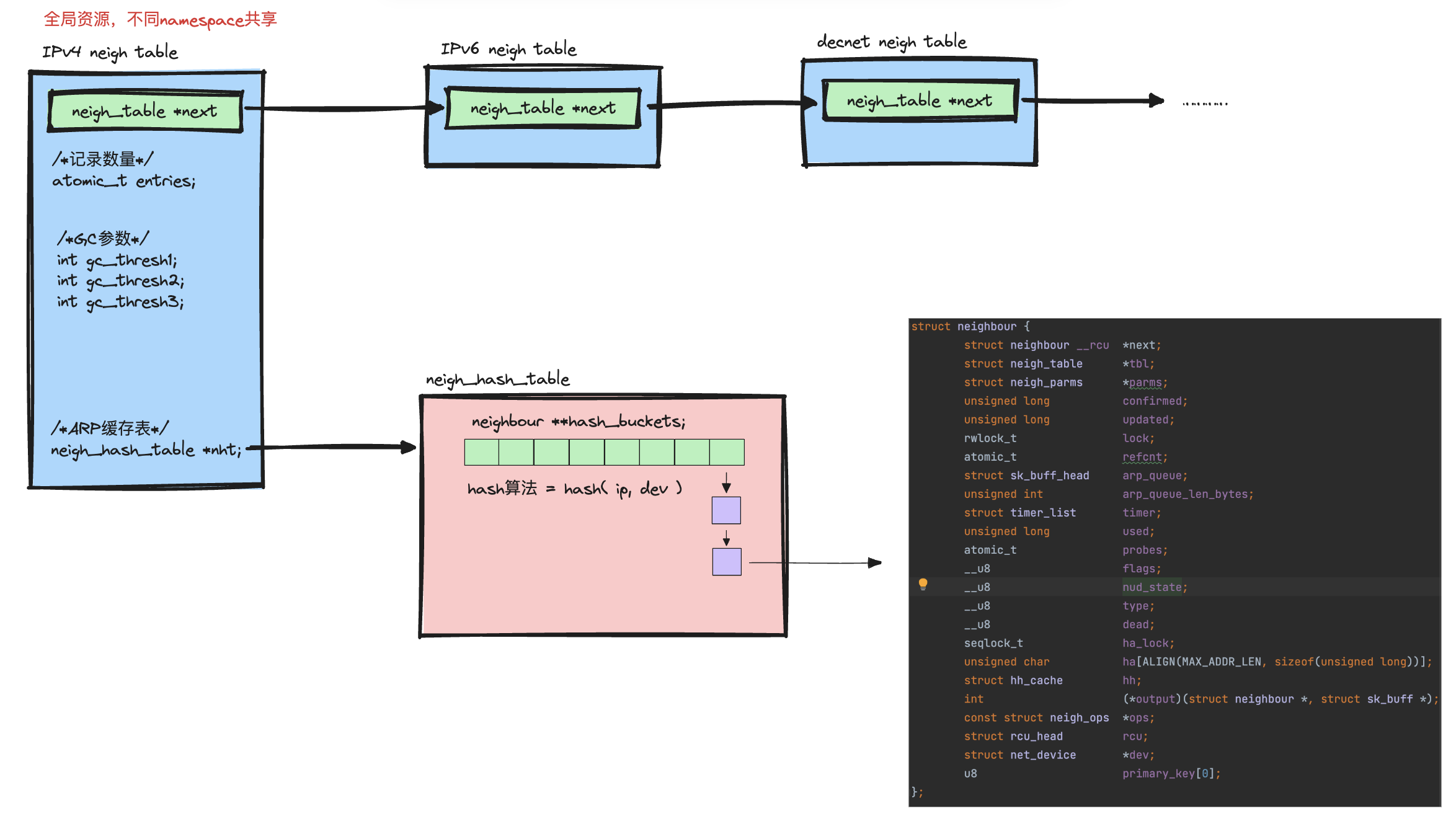
正常情况下,我们只能看到所在空间下的网络设备,因此只会查询出当前网络设备关联的记录(因为network namespace的网络设备隔离,neighbour记录中其实也记录其对应的dev)。我们可以去不同的network namespace中看看各自的ARP列表。
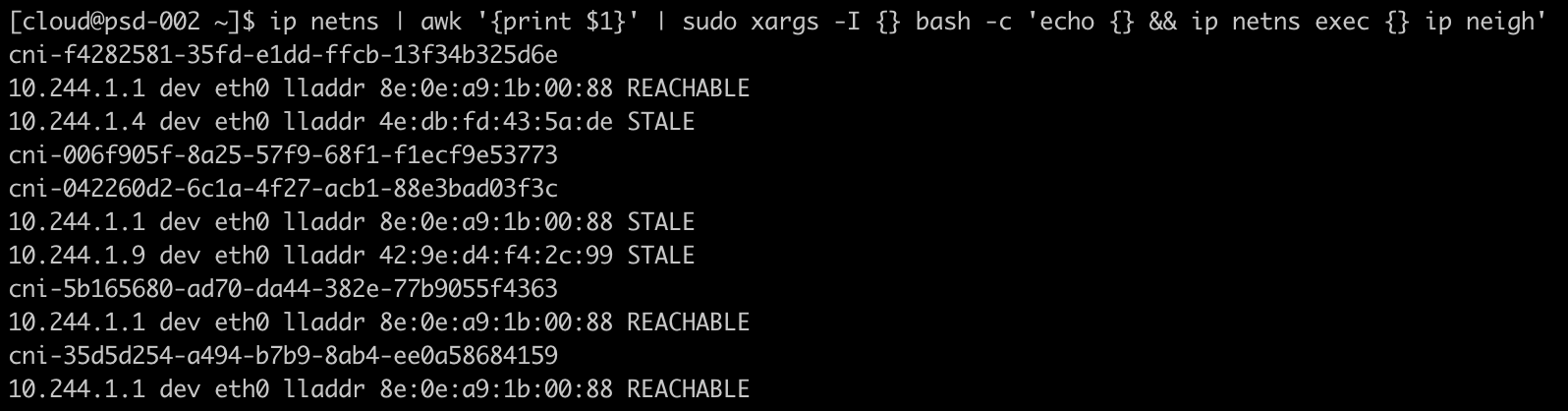
看到的结果其实是每个network namespace中,和其中的虚拟网络设备关联的ARP记录。比如,cni-f4282581-35fd-e1dd-ffcb-13f34b325d6e下有两条ARP记录,网络出口对应是该网络空间下的eth0。
那既然ARP缓存表是全局资源,那么就是所有network namespace共同使用同一个缓存表,那么如果单台宿主机上如果有非常多的Pod,有没有可能会导致ARP缓存表满,进而导致DNS解析失败呢?
问题复现
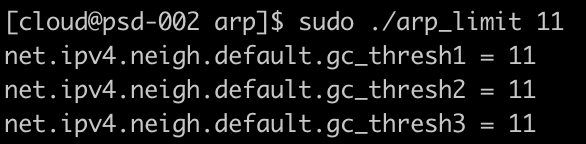
要模拟这个过程并不复杂,只要把ARP缓存GC阈值改小就好了。
首先,我们把neigh.default.gc_thresh的三个值全改成10。
然后在容器A里发起ping www.baidu.com时发现会阻塞住一段时候,并最终报错。

我们对cni0进行抓包后,可以看到下面结果。

我们还原一下整个过程。
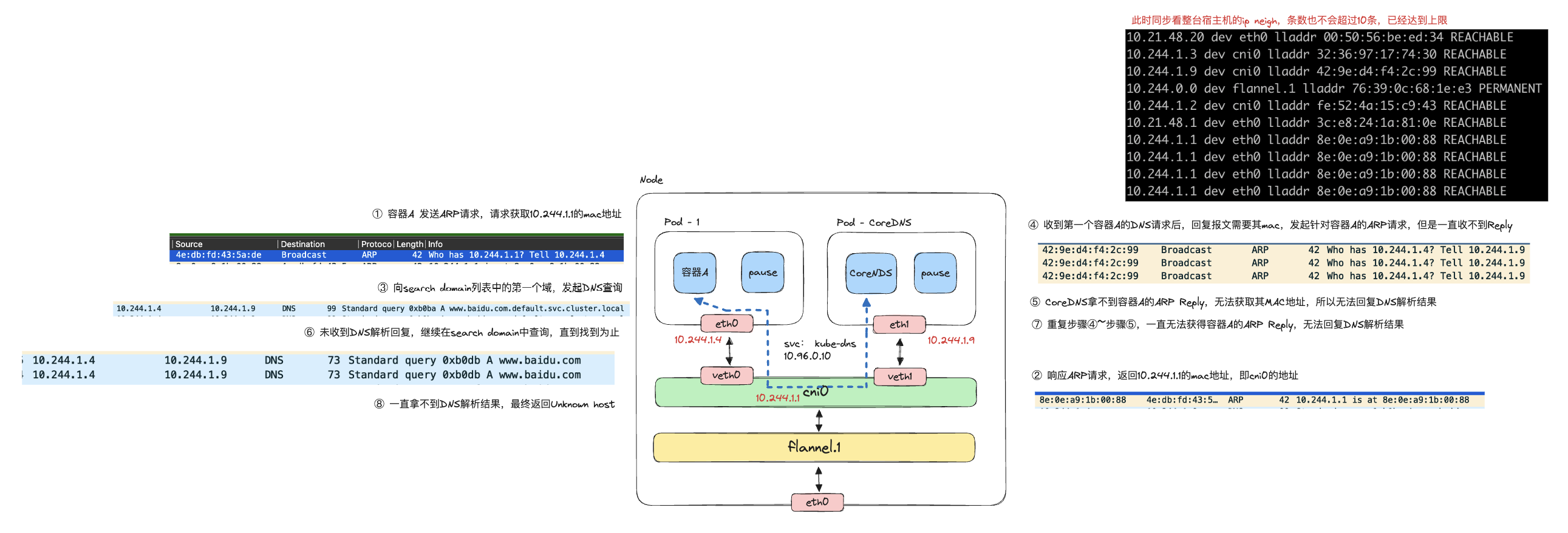
可以看到,此时CoreDNS为了向容器A回复DNS解析结果,需要通过ARP请求获取到容器A的MAC,但是由于ARP缓存表已满,此时A即使收到了ARP请求也无法进行回复。
net/ipv4/arp.c#arp_process
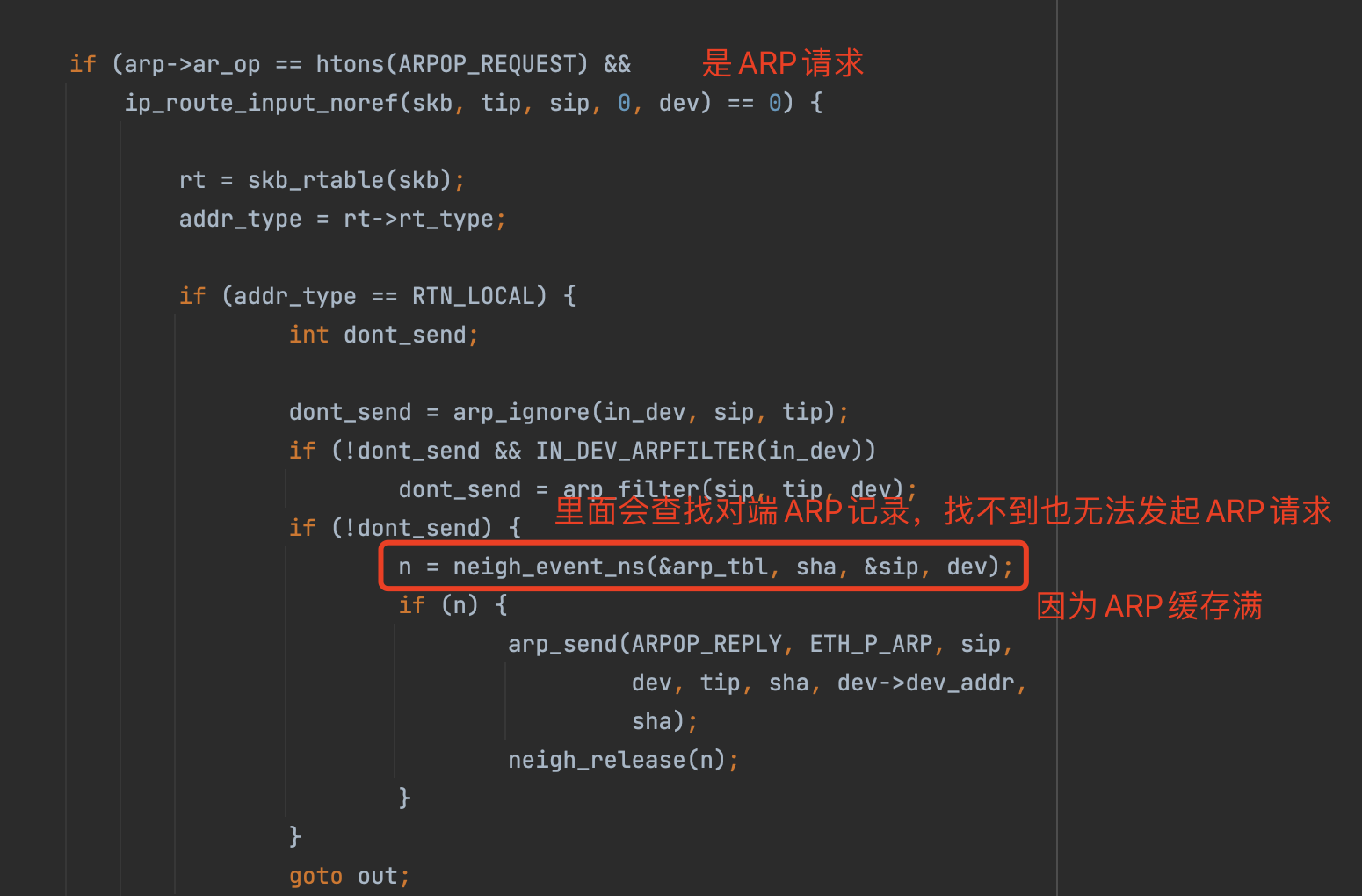
1 | |
解决方案
既然知道了原因,解决方法也比较简单,调大ARP缓存GC策略的阈值即可。

问题总结
问题本质上是由于ARP列表满,导致向CoreDNS请求DNS解析的过程中,容器之间无法正常请求或回复导致。
一般正常情况下,很少会发生这个问题,但是当单台宿主机的Pod数量较多时,就很容易到达这个上限。