在做 SQL 优化时,我们会 explain 语句查看 MySQL 执行计划,在最后的 Extra 字段中常常会看到using filesort,想必大家也一定不陌生。
当需要进行排序,而现有索引无法利用时,MySQL 需要通过额外的排序方法来满足 SQL 查询,此时语句的查询计划中就会出现using filesort,通常情况下我们会通过增加索引、LIMIT 行数限制来进行优化。
同时,你心里可能也会有些疑问,
- MySQL 是怎么做
filesort的呢? filesort一定要使用临时文件吗?- 使用什么排序算法?
- 当排序字段和数据字段不同时,一定要回表查询数据字段吗?
接下来,我们以由浅入深的方式,从基础流程、源码来看看 MySQL 的filesort。
(以下内容基于 MySQL 8.0 +的源码进行分析,与过往看到的以 5.7 为主的filesort过程可能会有不一致)
filesort 概览
在此之前,我们可以先来做类比,看看这样一个问题:
把大象放入冰箱需要几步?
答案大家都能脱口而出,需要三步:
打开冰箱 -> 把大象放入冰箱 -> 关上冰箱
类似的,filesort的整体过程其实也很简单:
读取数据 -> 数据排序 -> 输出结果
乍看之下,是不是有种“我上我也行”的感觉?
先别急,我们把步骤拆细,来看看 MySQL 围绕这几步,都做了哪些事情。
整体流程
通过一张图看看整个filesort过程,随时我们再逐步拆解每个步骤。
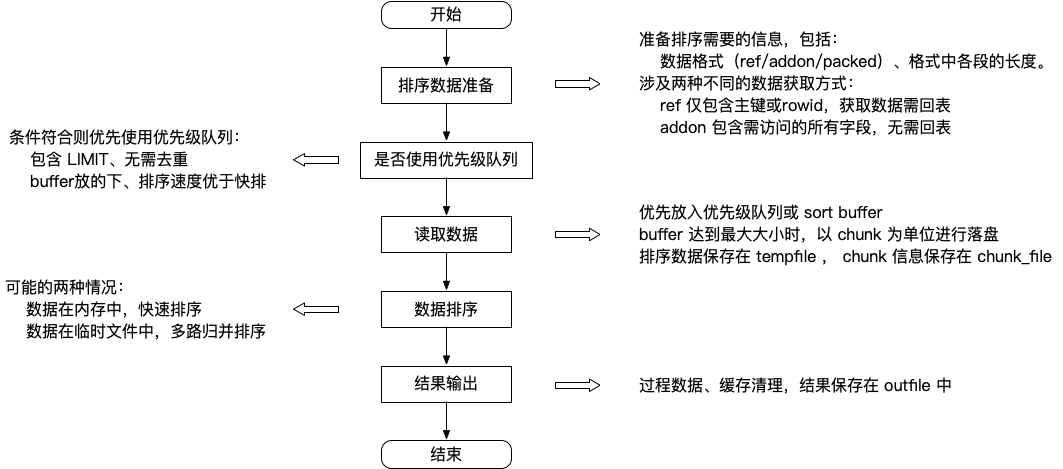
动手之前先准备 - 排序数据准备
在取出数据之前,MySQL 先为数据排序所需要的内容进行了准备,存储在Sort_param上,主要包括排序字段长度、去重、稳定排序等。
1 | |
这些数据都是为之后排序做准备,使用不同的获取数据方法、数据格式时,都依赖着这些参数。要想理解这些参数,需要首先了解ref、addon以及排序数据的组织格式。
ref 还是 addon ?
在排序数据准备的过程中,有非常重要的一步:
1 | |
init_for_filesort 会初始化排序过程中需要用到的过程信息,包含记录长度、去重、稳定排序等等,这些信息都包含在了Sort_param中,要理解其中字段的含义,需要首先区分两个概念:ref和addon
- ref,主键或rowid,主要用于排序后的回表查询
- addon,需要访问的字段,对应 SELECT 中的字段,排序后无需回表
MySQL 在获取数据的时候,除了获取 sort key 字段外,还会获取ref或者addon拼接在 sort key 之后,用于获取 SQL 语句中查询的字段数据。
但是,怎么决定使用哪一个呢,选择其中一者也决定着后续的查询字段的获取方法,选用ref意味着需要通过主键或rowid进行回表,以获取查询字段数据,选用addon则在一开始就需要把查询字段数据一起取出,减少了一次回表。
源码里,在decide_addon_fields(...)中做出了解答:
1 | |
除了一些特殊情况外(比如全文索引、强制 rowid 查询、使用优先级队列排序等,定义在了sort_param.h/Addon_fields_status),MySQL会优先使用addon。
关于
max_length_for_sort_data在老版本 MySQL 中,当
sort key之外的字段数据大于该值时,会默认采用ref,而在新版本MySQL(8.0)中,该字段已标识废弃,在未来将不再使用。
数据格式
在排序信息中的参数很多,各种length也很难理解每个字段的含义,我们换个方式,通过不同场景下的数据格式,来看它们的意义。

不难发现,在使用不同的记录格式时,记录长度会发生变化,所以需要单独计算各个段的长度。其中,rowid format对应前面的ref,addon format对应addon,而packed addon format是对addon format进行打包压缩的格式(例如对变长字符串打包,减少空间占用,同时针对blob、deciaml等也都有打包方法)。
有没有可能走捷径 - PQ优先级队列
准备好排序基础信息,并决定了数据格式,正常来说就要开始获取数据了。
但是,在这里 MySQL 会先做一个判断 ,检查是否可以使用优先级队列。那么,什么是优先级队列、为什么要用呢?我们一步步来看。
什么是 PQ 优先级队列
PQ(Priority Queue) 优先级队列,不同于普通队列,是按优先级大小出队的,其结构是一个完全二叉堆,堆中的父节点优先级一定大于子节点,在队列的维护上也有其规则:
- 入队列,先加入队列尾部,再从下至上调整二叉堆结构以满足规则
- 出队列,只能从堆顶出,再自上而下调整二叉堆
为什么使用优先级队列
这个问题可以换个角度,优先级队列的适用场景?
它的排序性能相比快排等算法,并不一定是最好的,但是在特定有限集合下的非严格排序、最值筛选维护可能会有更快的速度。例如,找到100个数里最大的两个数字,一种方法是全排序后取 top2 ,还有一种就是用优先级队列,队列只有两个值,通过不断入出队列找到 top2,性能会比全排序更好。
什么场景下使用优先级队列
回到主题,MySQL在什么情况下会使用呢?
从源码上看,判断的逻辑记录在了check_if_pq_applicable(...),在下面几个场景里,不会使用:
- 没有
LIMIT
前面说到算法在有限集合下的排序筛选可能会取得更好的性能,如果 SQL 中没有使用LIMIT,那么就不会使用 。这也很好理解,如果队列大小等于集合大小,那么不如换用其他排序算法(例如快排 )。
- 需要去重
和优先级队列的结构有关,其数据间不是严格的优先级大小关系,只能保证子节点优先级小于父节点。
- LIMIT 过大或数据过长
- 排序数据可以全部放在缓存里时,快排速度快于优先级队列
当所有排序数据可以放在内存时,MySQL 是可以使用快排的,这时就需要对比两者的速度。MySQL 认为优先级队列比快排慢 3 倍,当(排序数据行数 / 3)< LIMIT行数时,选择快排,否则选优先级队列。
- LIMIT 行数无法放在缓存中
优先级队列排序需要在内存中进行,那么就要判断缓存是否放的下 LIMIT 行数据。
终于进入第一步 - 读取数据
在开始读取数据前,先来看看我们准备好了哪些数据:
- 排序基础信息,包括数据格式、格式各段的长度、最大数据行数、是否使用优先级队列等
- MySQL 全局 or 会话配置,核心配置包括 sort_buffer_size 等
- 数据源迭代器 source_iterator,用于获取数据
基于这些内容,读取数据的过程如下: (尝试画流程图会有点绕,直接看官方伪代码,隐藏了部分细节)
1 | |
整体思路就是优先将数据读取到优先级队列或sort buffer,buffer 空间不足时进行申请扩容,无法申请新空间时则以chunk为单位保存到临时文件tempfile。其中,单个chunk的大小等于sort buffer大小,tempfile用于保存数据,merge_chunk用于保存chunk相关的信息,
同时在这个过程中,也会涉及一些问题:
- 数据入优先级队列,不用判断队列大小?
正常情况下不判断队列大小是有问题的。当队列满时,push操作不会报错,会直接丢弃对象,我们无法知道实际操作是否成功。因此,在读取数据前,MySQL 提前判断了是否使用优先级队列,只有数据能放在缓存中时,才会使用。
- 读取数据过程中,查询被终止会怎么样?
查询终止则读取也要终止,MySQL 会在每一次通过source_iterator读取数据后,查询检查是否已经killed,如果是则抛出异常。
1 | |
- 空间不足时,会先排序再落盘,使用什么方法排序?
使用的是快速排序,对应源码在Filesort_buffer::sort_buffer中。
- 为什么保存在chunk前,要先排序?
这就涉及到最终的结果排序了。由于sort buffer放不下,就会导致取出的数据分散在不同的chunk_file中,但是最终是要全数据排序的,这种多文件数据排序的场景,最适合的就是归并排序,chunk_file中数据的有序是为了后续的归并排序。
- chunk_file 与 tempfile 的关系?
当sort buffer满时,会将整个 buffer 作为 chunk 保存在 tempfile 中。其中,所有的 chunk 都保存在同一个tempfile ,这就需要一个结构来记录 chunk 在tempfile中的位置、大小等信息,这个结构就是 merge_chunk,该结构保存在chunk_file中。
不同的场景不同的方式 - 数据排序
读取完数据,有两种可能的结果:数据在内存中、数据在临时文件中,通过num_chunks进行判断,大于 0 则以为着有数据在chunk_file中。
- 数据在内存中
直接使用速度最快的快速排序,在内存中完成整个过程。
- 数据在临时文件中
MySQL 使用归并排序算法实现所有chunk的排序,核心使用多路归并算法,同时整过过程和两个参数有很大的关系,MERGEBUFF(7)和MERGEBUFF2(15)。
当剩余的chunk数量小于MERGEBUFF2(15),一次性归并所有chunk得到结果;(源码实现记录在merge_index(...)中)
当剩余的chunk数量大于MERGEBUFF2(15),以MERGEBUFF(7)为一批进行归并排序,合并为一个更大的chunkd,直到小于 15 。(源码实现记录在merge_many_buff(...)中)
通过多次的归并排序,最终会合并到一个有序的数据集。
如果排序过程中,查询被终止了怎么办? 在排序过程中,也会埋设检查点,检查查询是否被终止,即判断
thd->killed是否为 true。
终得正果 - 结果输出
排序最终会输出得到一个完整的有序数据集,记录在outfile中,而在返回真正的数据集前,会进行缓存(sort buffer等)、临时文件(tempfile、chunk_file等)的清理。
总结
最后我们回过来,来回答最初的几个问题。
- MySQL 是怎么做
filesort的呢?
回到最初的这张流程图,说明了整个filesort过程。
filesort一定要使用临时文件吗?
不一定,当sort buffer能放下待排序数据时,是不用临时文件辅助的。
- 使用什么排序算法?
filesort使用到了三种排序算法:
- 优先级队列排序。获取数据前判断是否可以使用,用于优化 SQL 包含
LIMIT且排序效率高于快排的场景 。 - 快速排序。排序数据全部放在
sort buffer中,主要用于内存排序。 - 多路归并排序。单个
sort buffer放不下数据,需要落盘辅助时,使用多路归并排序合并多个chunk,最终合并为一个有序的结果集。
- 当排序字段和数据字段不同时,一定要回表查询数据字段吗?
不一定,取决于排序信息准备阶段判断使用哪一种数据格式。