在去年八月份,我们的产品上线了新功能,场景如下:
(1)用户在开放场景下相互关注
(2)用户可以发布个人录音
(3)用户在个人首页可以收听其他人的录音

这属于很典型的Feed流场景,类似新浪微博、微信朋友圈。用户生产内容,平台再将内容分发传递给用户。
业务初期,功能实现的很简单,只保留最基础的用户关系和录音记录。当用户在个人首页查看其它用户录音时,会转化为这样一个流程:
(1)找到用户所有的关注人
(2)获取所有关注人发布的录音
(3)时间降序排列后,按页取数据
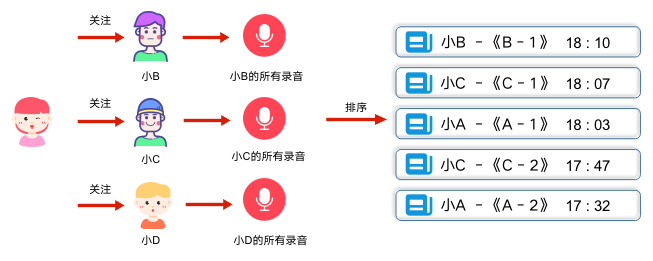
刚开始用户少活跃低,这样简单的设计实现既能满足需求,成本也很低。但是随着时间推移,问题逐渐显现。
随着用户不断增多,用户关系逐渐复杂,用户发布内容不断增加。功能接口开始出现延时告警,部分SQL操作耗时达到7s以上:
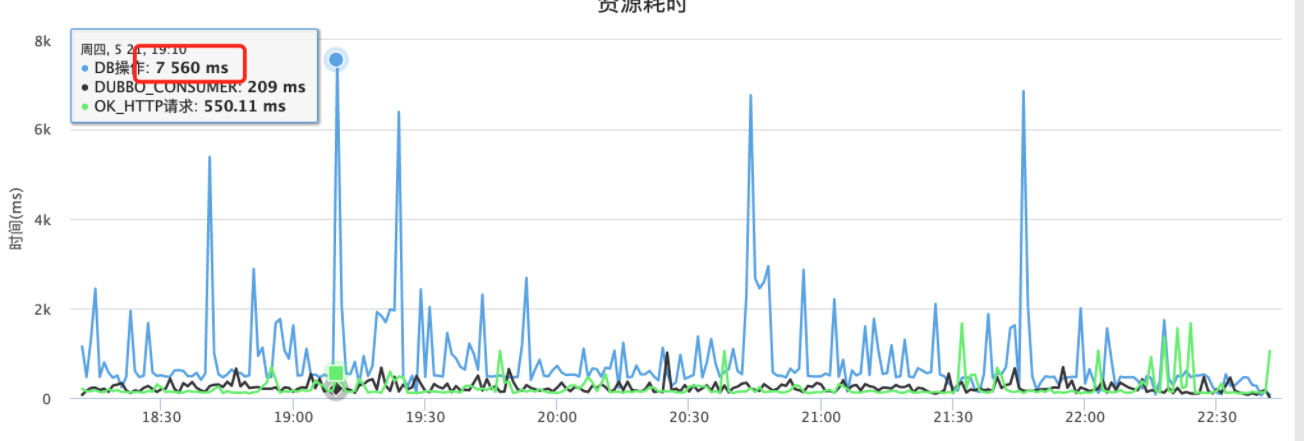
在针对SQL进行分析后,我们发现问题出在关注人录音的获取和排序上。一些头部活跃用户,关注了上万人,而单个用户平均发布几十个录音,这就意味着每一次获取列表时,拉取的数据量 = 关注人数 * 发布录音数,将几十万数据拉取到内存中排序和分页,成本很高。想解决这个问题,需要回归Feed流本身。
Feed流
先来看看 Web Feed 是什么:
1 | |
从定义中可以看出,feed 是一种数据形式,向用户提供持续更新的内容。持续的内容符合流本身的特征,而其中内容则是关键。在内容展示上,通常需要解决两个问题:
1 | |
在不同的场景下,例如微博、微信和知乎等,会有不同的答案,我们来对比一下:
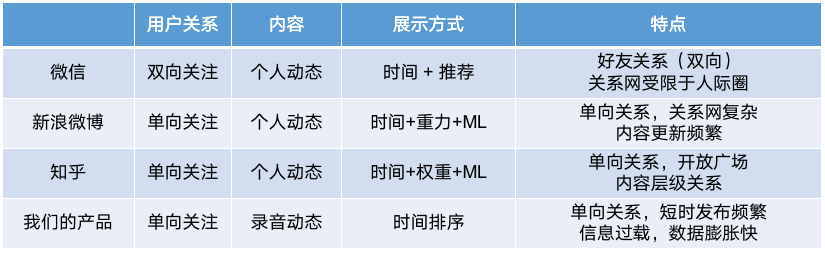
在我们的产品场景中,
(1)用户关系建立简单,只需要满足单向关注关系。内容上呈现用户录音,录音自动发布,短时高频生产内容,数据膨胀速度会很快
(2)从展示方式上看,目前较为单一,属于典型的Timeline,严格有序
解决方案
在Feed流场景中,通用方案是基于用户收发件箱的推拉流方案。
收发件箱是什么?字面理解,每个用户都有属于自己的收件箱和发件箱。发件箱比较好理解,用户发布的内容都会保存在自己的发件箱中。那么收件箱呢,什么内容会投递到收件箱、谁会投递到收件箱、投递的时机,这就和具体的推拉方案有关。
- 拉模式:
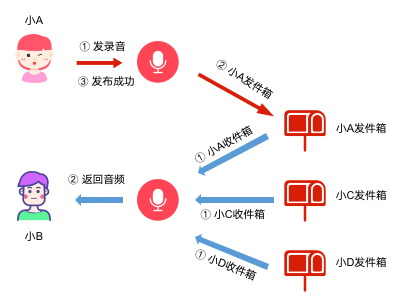
业务最初使用的方式就是拉模式,发布动态存入个人发件箱,拉取动态则先获取所有关注人,再一起拉取排序。
这种方式很简单,也有其优势:
(1)易于维护。内容生产投递发件箱,流程短数据关系简单。用户关系发生变化,Feed 流内容会随之变化,不需要额外的处理
(2)开发成本低。适于业务早期功能快速开发上线,或者可预估的未来里,产品体量(用户、内容)不会很大的时候使用
同时拉模式的缺点也是很明显的,就是读扩散。需要同时拉取多个用户的收件箱,实时聚合排序计算,当用户关注人数和生产内容越来越多时,这个有问题尤为明显。
- 推模式

推模式则是通过引入用户收件箱的概念,来解决拉模式中的读扩散问题,内容产生时,需要考虑收件箱的投递:
(1)用户发布内容,放入用户个人发件箱
(2)获取用户所有粉丝
(3)往所有粉丝的收件箱中,投递发布的内容
在推模式下,用户拉取动态时,只需要从自己的收件箱获取,省去了实时聚合排序计算,读性能可以得到大幅度提升,有效解决了拉模式的读扩散问题,但同时也引入的新的问题:
(1)写扩散。用户发布动态,需要往所有粉丝的收件箱里写数据,对写性能有要求
(2)用户关系发生变化时,需要额外逻辑过滤和处理收件箱内容
有了方案,也会翻船
有了推模式和拉模式,在面对 Feed 流场景时,就可以根据业务场景匹配不同模式进行使用。在经过讨论后,我们初步决定将业务逻辑改为推模式。
但是,做完了选择,确定了方案,就能一帆风顺不翻船吗?答案当然是不。
我们随机抽取了60W用户,模拟纯推模式下的效果,发现收件箱数据总量达到2亿条,随着时间推移,数量还会不断增长(用户新增、用户新动态发布),数据存储和读写会逐渐出现问题,以MySQL为例,单表数据量过千万时性能就会开始下降。那么问题来了,这么多数据怎么办?
- 技术优化
面对性能问题,首先会想到从技术的角度上来做优化。
(1)分表 单表数据量过大,首先先到的就是拆,数据分表。在我们的业务场景中,是以用户为粒度,获取单个用户的收件箱,那么按用户ID进行Hash拆分是最直接的方式,优点是逻辑简单,缺点是扩容复杂,需要重新Hash。
(2)冷数据迁移 本质上还是拆,只是拆分逻辑不太一样,基于时间来做。这个思考源于Feed流本身的特征,它提供的是不断更新的内容,用户接收最新的讯息动态,旧内容则不断下沉,时间久远的内容很难被翻出来。 举个栗子,以年为周期拆分,今年的数据就是热数据,去年前年的数据都是冷数据。冷数据单独迁移保存,访问少,存储介质选择机械硬盘,成本低。热数据访问概率大频次高,可以存放在SSD上,同时做缓存加速。
(3)其他 缓存、中间表、预计算等等,都能起到作用,但是治标不治本,没有根本解决数据量大的问题。
- 换个角度,从数据下手
既然数据量大,那就从数据下手,看看数据的特征,从业务上进行优化。
(1)“大V” 我们先从动态发布人的角度,来看看带给粉丝收件箱的写数据量。
同样随机取60W用户,得到这样的数据结果:
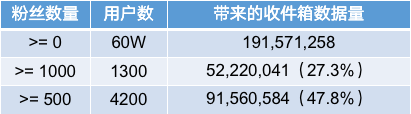
60W用户带来的收件箱数据量在1.9亿左右,其中有接近一半(47.8%)的数据产生自4200个粉丝数量大于500的用户。这部分用户虽然不多,但是他们的粉丝多,动态发布频繁,活跃度高,我们通常称之为“大V”用户。
“大V”用户作为社交媒体类产品中的头部用户,是优质内容的生产者,他们往往拥有非常庞大的粉丝群体,在内容生产上,“大V”用户的生产频率也会更高。在这个场景中,如果单纯的采用推模式,“大V”用户生产内容时,推模式带来的写扩散影响是很大的,写入收件箱的数据量也很庞大。
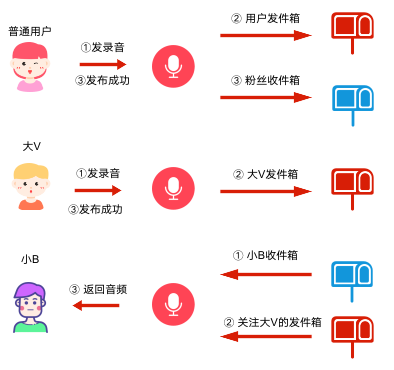
所以,在这个场景下,一般会采用推拉结合的模式,普通用户发布时采用推模式,”大V“用户发布时采用拉模式,那么整个Feed流的业务流程也发生变化:
(2)非活跃用户
继续从数据出发,收件箱动态是给粉丝用户看的,那么也看看粉丝用户。当粉丝用户上线活跃时,就会拉取动态查看最新的Feed流信息。但是,用户都是活跃的吗?当然不是。
因此我们也做了一次数据推算,同样抽取60W用户,看非活跃用户群体收件箱的数据量:

可以看到,接近82%的数据都属于非活跃用户,占比非常高。 (这和我们的产品功能逻辑有关,导致这部分占比偏高)
面对这部分用户,我们应该怎么做?
(1)不主动推送给长期非活跃的用户,避免生产没有价值的数据。
(2)如果这部分用户恢复活跃(上线),再异步的为用户同步数据

真的这么做吗?
有了方案,也避免了翻船,看上去万事具备。但是,真的这么做吗?
在动手之前,先想想这样的一系列方案存在什么问题:
(1)业务复杂度高,维护、扩展成本高。设计三原则,包括合适、简单和演进,面对这样的复杂度,团队是否有充足的人力成本去开发、维护和扩展?当前已经业务逻辑已经很复杂,再引入这么高复杂度的模块,是不是我们需要的?我们真的要一次性做到这么复杂吗?冷静下来后,你会发现这并不是我们想要的。
(2)写扩散问题依然存在,对写性能有要求。虽然避免了大V用户发布动态时大量写的情况,但是对于普通用户来说,粉丝数量也不少,同时在我们的业务场景中,用户活跃集中在晚上,用户高频发布,对写的性能还是有要求。
(3)MySQL属于关系型数据库,存储时序型数据并不合适。
所以,最终我们并没有使用这些方案,而是换了个角度,从存储组件入手。(有空再写 HBase)